数据产品经理小王:
“老曹,上次你教我的Excel技能很好用啊,除了这个,我还想多掌握一些技能和知识,再给我科普一下呗!”
老曹一听,这小伙可以啊,上进爱学习,新时代好青年啊:
“小王,作为数据产品经理,你听过Hadoop吗?”
数据产品经理小王:
“what? 哈什么普?这是个什么鬼东西!???”

老曹一听,乐坏了:
“搞大数据,居然连Hadoop都不知道。Hadoop是一个分布式系统基础架构,现在被广泛地应用于大数据平台的开发,对处理海量数据,有着其他技术无可匹敌的优势。Google File System、MapReduce与BigTable被誉为分布式计算的三驾马车。Hadoop的基本架构的底层是 HDFS,上面运行的是 MapReduce/Tez/Spark,再往上封装的是 Pig 和 Hive!”
数据产品经理小王:
“听上去好专业啊,我感觉我咋还是不懂呢!”

老曹又拉出了他的小画板,开始在上面画起来:
“Hadoop的三大核心设计可以简要的表示为这个架构图。
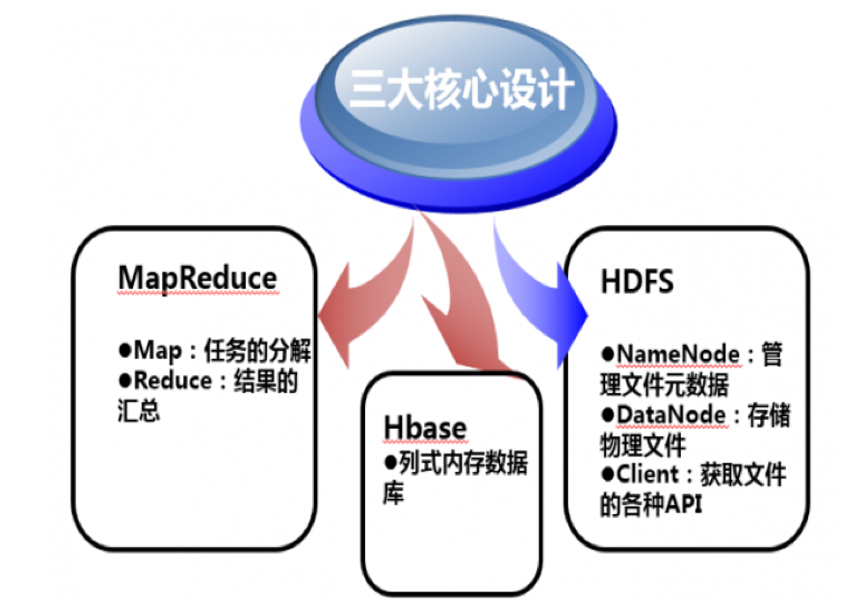
其中,Google File System是文件存储系统,主要用来解决数据存储的问题,采用多台分布式机器,使用灾难冗余的方式,既做到了数据读写速度的提升,同时也又能保证数据的安全。大数据技术首要的要求就是先把数据存下来,HDFS(Hadoop Distributed File System)为了解决存储的问题,把大量的数据通过成千上万台机器存储,而用户在前端看到的只是一个文件系统,而不是许多文件系统,是一种对用户友好的处理方式。比如,用户要获取 /hdfs/tmp/mydata的数据,虽然使用的是一个路径,但其实数据会分布式的存储在不同的机器上,而用户根本不知道到底存储在哪些机器上,当然也没有必要知道,这种处理方式就像在我们的个人电脑上,你不用关心文件到底存储在磁盘的哪个扇区中。HDFS会集中管理数据,用户只要把精力花费在如何使用和处理数据上。”
数据产品经理小王:
“大概听明白了,那么在解决了数据存储的问题之后,如何更高效地处理数据呢?”

老曹看吊起了小王的兴趣,接着说:
“如果让一台机器处理TB级或者PB级的数据,可能会花费几天甚至几周的时间,而这对于很多公司的业务来说是不可接受的。例如,这个图是微信搜一搜中的微信热点功能,需要小时级地更新数据,就需要很快的数据处理速度。
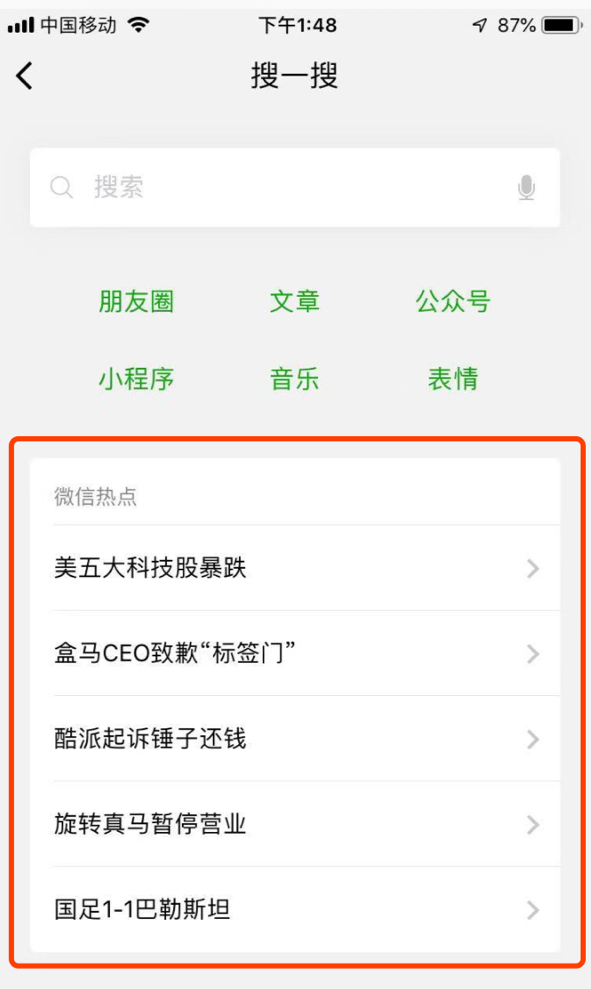
而MapReduce /Spark就是为了解决这个问题,它可以给并行处理任务的计算机分配的任务更加合理,并负责任务之间的通信,以及数据交换等工作。MapReduce /Spark提供一种可靠的、能够运行在集群上的计算模型。MapReduce会把所有的函数都分为两类,即Map和Reduce。Map会将数据分成很多份,然后分配给不同的机器处理;Reduce把计算的结果合并,得到最终的结果。
但是如果直接使用MapReduce 的程序,会发现使用门槛比较高,Hive和Pig基于MapReduce的基础封装出一个更友好、更简单的方式,可以很容易地实现MapReduce程序。Pig以类似脚本的方式实现MapReduce,Hive以SQL的方式实现。Hive和Pig会把脚本或者 SQL自动翻译成MapReduce程序,然后交给计算引擎执行计算。数据分析师由于经常使用SQL,所以Hive的使用门槛就变得更低,而且Hive的代码量比较少,一两行的SQL语句就可以解决很多问题,而如果使用MapReduce,可能需要上百行。所以,Hive得到越来越多的人青睐,并逐渐流行起来。”
数据产品经理小王:
“Hive这个名词我听说过,因为我在自学MySQL的时候,也了解过这方面,Hive用于存储一些大数量的离线数据很有优势啊,通过HQL提取数据也很方便。”

老曹心想终于开窍了啊,然后接着说:
“我给你画个图啊,这样有助于从大致框架和结构上理解Hadoop。
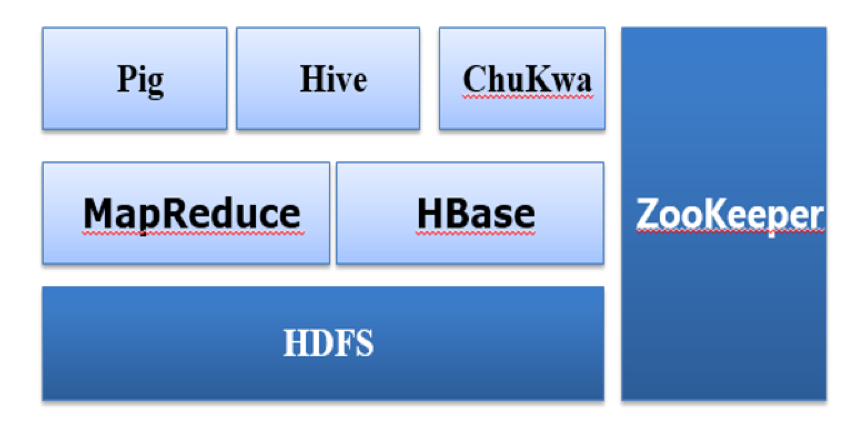
现在的Hadoop已经从上面提到的Hadoop三驾马车HDFS、MapReduce和HBase,逐渐发展为60多个相关组件构成的庞大生态家族,其中在各大发行版中就包含30多个的组件,包含了数据框架、数据存储和执行引擎等。”
老曹越说越文采飞扬:
“再给你展示一张神图吧, 它包含了目前最流行的两个大数据处理框架 Hadoop 和 Spark:
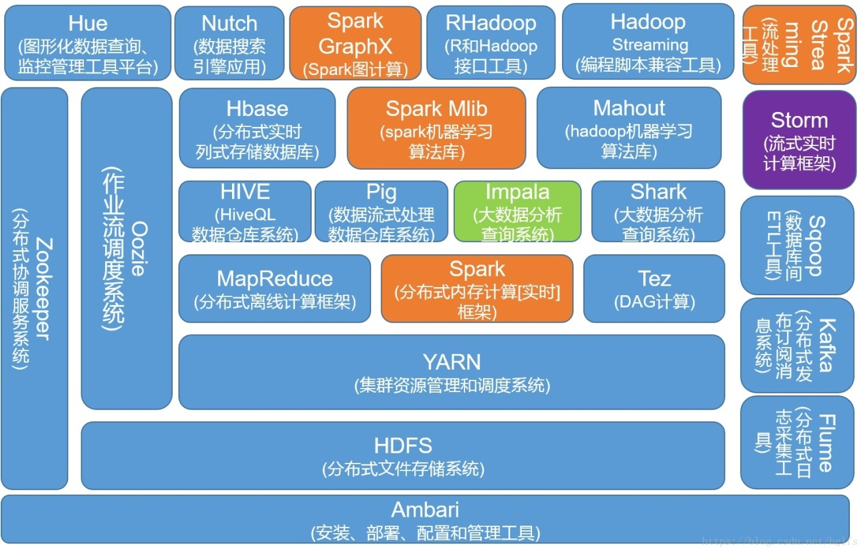
Spark、Spark Mlib、Spark GraphX和Spark Streaming组成了Spark 生态圈,其余部分组成了Hadoop生态圈组。这两个框架之间的关系并不是互斥的,它们之间既有合作、补充,同时又会存在竞争。例如,Spark提供的实时内存计算,会比Hadoop中的MapReduce速度更快。但是,由于Hadoop更加广泛地应用于存储,Spark也会依赖HDFS存储数据。虽然Spark可以基于其他系统搭建实现,但也正是因为它与Hadoop之间的这种互相补充的关系,所以Spark和Hadoop经常搭配在一起使用。”
数据产品经理小王:
“哇,原来这么多内容,涨知识了,总算有个体系化的了解了。”
老曹一看时间,还有10分钟到中午吃饭的时间,抓住时间跟小王说:
“我再给你拓展下吧,讲一下更多的工具和知识。”

老曹把画布上之前画的擦去,然后开始涂涂画画起来:
“除了Hadoop体系架构那些基础工具外,数据产品经理还需要对以下几个基础工具做一些了解。
Spark:Spark是一个开源的集群计算环境,刚才也说了,Spark与Hadoop之间既相关补充,又相互竞争。在优势上,Spark启用了内存分布数据集,在处理某些工作负载方面表现得更加优越,交互也会更加友好。
Kafka:Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理各大网站或者App中用户的动作流数据。用户行为数据是后续进行业务分析和优化的重要数据资产,这些数据通常通过处理日志和日志聚合的方式解决。Kafka集群上的消息是有时效性的,可以对发不上来的消息设置一个过期时间,不管有没有被消费,超过过期时间的消息都会被清空。例如,过期时间设置为一周,那么消息发布上来一周内,它们都是可以被消费的,过了过期时间,这条消息就会被丢弃以释放更多空间。
Storm:Storm主要应用于分布式数据处理,包括实时分析、在线机器学习、信息流处理、连续性的计算、ETL等。Storm主要应用于实时处理,被称为实时版的Hadoop,每秒可以处理百万级的消息,并且Storm可以保证每个消息都能够得到处理,具有运维简单、高度容错、无数据丢失、多语言的特点。
HBase:HBase是一个构建于HDFS上的分布式、面向列的存储系统。以 Key-Value对的方式存储数据并对存取操作做了优化,能够飞快地根据 key 获取绑定的数据。例如,从几个 P 的数据中找身份证号只需要零点几秒。
HUE:HUE 是 Cloudera 的大数据Web可视化工具,主要用来简化用户和Hadoop集群的交互。可以在Web界面把数据从HDFS等系统导入Hive中,可以直接通过HUE以Hive SQL的方式对数据查询展现。同时,还可以保存SQL语句,并查看和删除历史SQL语句,对于查询后的数据,可以选择表格、柱状图、折线图、饼状图、地图等多种可视化图形展示,操作十分简单,如果想继续分析,可以使用下载功能下载保存为Excel。同时,任务的执行进度、执行状态、执行时间等执行情况,都会以Web可视化的方式展现给用户,同时还能够查看错误日志以及系统日志等。如果小规模的公司没有自己的大数据管理平台,那么它们还可以通过HUE查看元数据信息、任务调度执行情况等,方便对数据资产及调度进行管理查找等操作。
Oozie:Oozie 是一个工作流调度系统,统一管理工作流的调度顺序、安排任务的执行时间等,用来管理Hadoop的任务。Oozie集成了Hadoop的MapReduce、Pig、Hive等协议以及jave、shell脚本等任务,底层仍然是一个 MapReduce程序。
Zookeeper:ZooKeeper是Hadoop和Hbase的重要组件,是一个分布式开放的应用程序协调服务,主要为应用提供配置维护、域名服务、分布式同步、组服务等一致性服务。
Yarn:Hadoop生态有很多的工具,为了保证这些工具有序的运行在同一个集群上,需要有一个调度系统进行协调指挥,Yarn就是基于此背景诞生的资源统一管理平台。”
数据产品经理小王:
“厉害了,我的哥,打开了我新世界的大门,终于知道Hadoop是什么了。”
老曹感觉感觉差不多了,对小王说:
“其实这些,你有个基本概念就行,毕竟会有技术同学去帮你实现Hadoop相关的问题。通过我刚才给你讲的知识,可以让你对整个体系比较了解,还方便与研发同学交流。好了,我们一起去吃饭吧。”

后续,公众号“一个数据人的自留地”会持续更新老曹入职公司后,作为数据产品经理的工作过程中的经历和心得,希望对各位有所帮助和启发,如果有共鸣,也欢迎大家留言、投稿,让“一个数据人的自留地”,成为一个有温度的数据社区。

一个数据人的自留地是一个助力数据人成长的大家庭,帮助对数据感兴趣的伙伴们明确学习方向、精准提升技能。
扫码关注我,带你探索数据的神奇奥秘





发表评论 取消回复