@知乎:鲸歌 电商行业数据分析师; 为头部品牌提供数据咨询服务; 热衷学习与分享; “数据人创作者联盟”成员。 01 背景信息
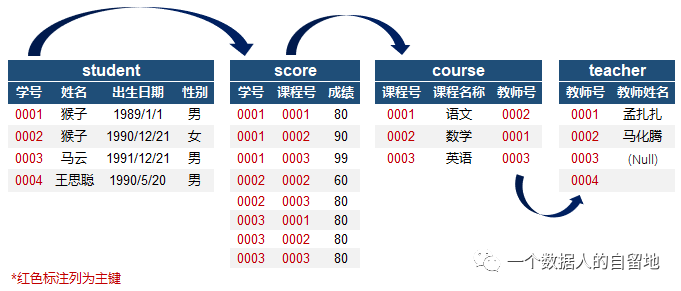
工具:mysql数据库+navicat数据库管理客户端; 数据库&报表:School数据库,包含4张报表分别是student、score、course和teacher 报表明细信息:别看表格很小,其实能量巨大,真实业务场景会涉及更多报表以及海量数据,两者本质一样,区别在于数据量的多寡。倘若能够把4张报表实操顺溜,那么日后遇到巨量数据也不怕不怕啦~
02
阅读指南

日常Sql解决业务问题的步骤:翻译成大白话→写出分析思路→写出对应sql语句; 字符串模糊查询:like + % + _ 组合,%表示任意字符串,_特定单一字符串,%和_使用位置根据问题的要求而定; Count()函数:与计数相关,常与distinct联用,以区分是否剔除重复值; As:为表格原始字段或表名设置简单别名,方便书写 Sql语句执行顺序:from子句→where子句→select子句;
在业务场景中,简单查询适用于提取临时数据,比如活动中某一时刻的订单数量、赠品数量和下单用户量等,在分析问题时也可以基于某个分论点快速提取相关数据进行验证。

聚合函数有:count()、sum()、avg()、sum()、Max()、Min(); Group by 分组:分组后跟的列名与select后保持一致,分组可有多个列名,但多个列名保持1对1关系,避免因关系紊乱而报错; Where子句与having子句区别:having后可跟聚合函数,where不可以,having位置跟在group by后; Order by 排序:desc降序、asc升序,默认asc可省略,多个列名同一排序规则可只写一个desc/asc,不同列名不同排序需对应指明;

子查询:判断是否需要子查询和需要哪种类型,普通子查询(返回多行结果)、标量子查询(返回单行单列)和关系子查询(每组之间进行比较); Sql语句书写顺序:先写子查询,再把子查询嵌套主查询中,若有多层嵌套,注意嵌套顺序,如上题子查询中还有子查询; Sql运行顺序:先运行子查询,其次运行from、where、group by 和having,再select,最后是order by和limit子句;
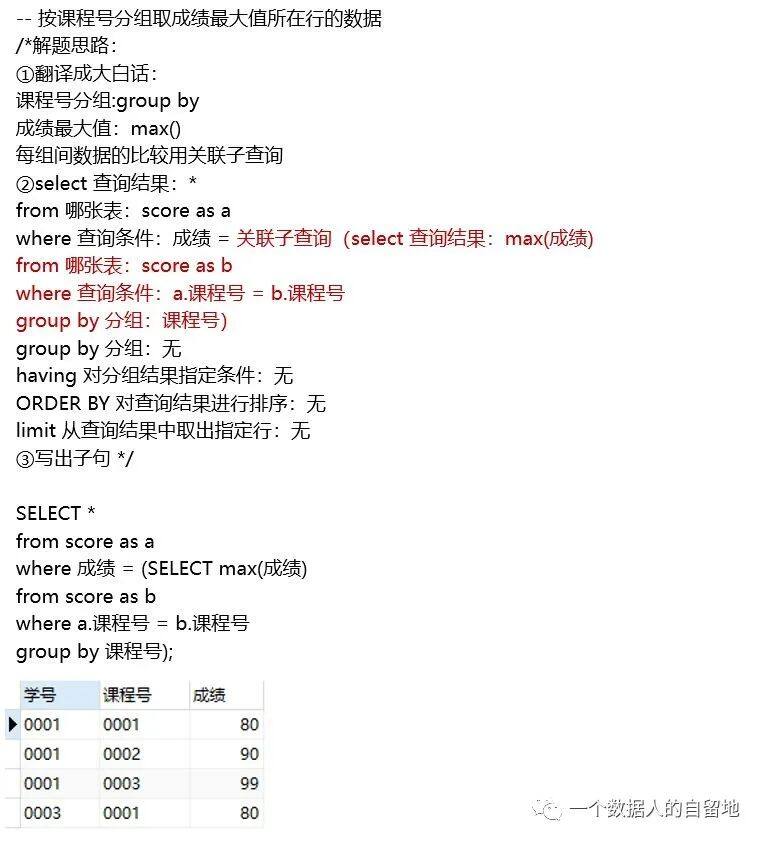

Order by 排序:分辨升序和降序的区别,asc是数字由小到大,desc是数字由大到小; Limit 提取特定行数:limit n = limit 0,n,比如limit 5 是提取前5行,limit 2,3是从第3行开始提取3行(包括第3行); Union all:表的加法,区别于union,union all允许重复值存在;

 图片来源于:猴子聊数据分析
图片来源于:猴子聊数据分析

那么,在提高SQL查询的效率上,我们需要知晓哪些呢?

想了解更多数据知识也欢迎看,7位大厂数据产品写的《大数据实践之路:数据中台+数据分析+产品应用》这本书。



发表评论 取消回复