关注微信公众号:一个数据人的自留地 Simba IBM资深商业分析师。 IT老兵。 终生学习者。 欢迎回来,本篇从一个基本概念——留存谈起。面试的时候“留存”也是大概率会被问到的一个问题,如果想确认自己的回答怎么样,我们一起探讨一下。本文约4000字,读完需要10分钟。 01 留存怎么算 “留存不就是用户在未来xx天的使用情况么,比如第一天拉新1000,第二天有100个人来了,留存率10%。” 这个算法本身没有问题,就比如前文中的一个例子: 有一个鼓励试用的活动持续2天,我们来看3日留存率的计算。
10月1日,1000人试用;第一天这1000人中300登陆CRM软件;第二天,有200人登陆CRM软件;第三天,有150人登陆CRM系统。
10月2日,1500人试用;第一天有400人登陆CRM软件;第二天有200人登陆CRM软件;第三天有150人登陆CRM系统。
那么针对10月1日和10月2日这两天的活动,三天的留存率分别是这样的(蓝色内容所示):

但是要反映整体活动的3天留存率,应该怎么计算呢。我的方法是,把这几天活动中第X天的留存总人数,除以这几天拉新的总人数,即:
第一天整体的留存率为:
第一天的留存的总人数之和/这几天活动拉新的总人数
第二天整体的留存率为:
第二天的留存的总人数之和/这几天活动拉新的总人数
……
以此类推,如下图中绿色内容所示:

这也是我在上文中提到的方法,然而一位小伙伴提出了他的看法(如果这位小伙伴看到此篇,可以联系我哦~)。

于是我把具体计算方法放在更大群体里讨论,不同的声音出现了,那种情形就像一帮南北方朋友在我家聚餐,我在西红柿炒鸡蛋里准备放糖,被一个北方人看到后大声质疑:“西红柿鸡蛋不要放糖啊”, 然后另外一帮南方人马上回答“啊,当然要放糖啊”。
“留存算同一周期下的平均值会好一点, 不是和的平均,而是百分比的均值”, 所以这里的另外一种方法是这样的,把两天的留存百分比加起来,除以总天数,即:
第一天整体的留存率为:
(10月1日的day1留存率+ 10月2日的day1留存率)/2
第二天整体的留存率为:
(10月1日的day2留存率+ 10月2日的day3留存率)/2
……
以此类推(如下图橙色内容所示):

貌似两种算法看起来结果都差不多,可是又有另外一个声音出现了:
“一般情况下两种算法所得值差不了太多,但是如果两天的拉新数量差别很大,留存比率差别也大的情况下,就会出现不一致的情况, 比如下面这个例子,按照第一种方法算出来是2.75%, 第二种方法算出来是46%。”

哇,那要怎么算。“第二种用加权平均去算就好了,权重可以用拉新人数来算。”于是衍生了第三种算法,但仔细一看,按照拉新人数加权算其实和第一种算法是一样的(如下图第三行浅绿色所示)。

此时另外一个声音将话锋转移到一个新的问题:“先不去讨论对错,你们有想过这两种算法在业务应用上的差异点么?忽略场景而言,对绝大多数运营的人来说,肯定会先盯这个数字;因为第一条数据里98%的流失,需要反思的事情太多了,后面的更容易去做策略的落实,有方向和动力。”
所以为了体现这种异常,我们需要全局全细节的留存信息,就回到了最初的阶梯式留存表格,利用热力图将异常值高亮显示(比如下图),让业务人员一眼看到异常来展开分析,并且这些异常值后面往往蕴藏着机会或者风险,或者——bug。
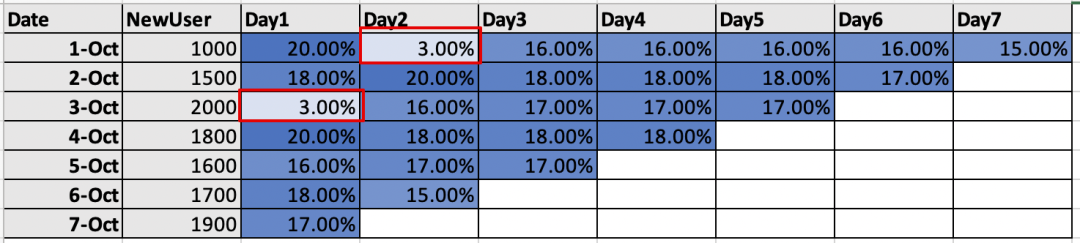
但是,如果要更准确的体现整体活动的3天留存率,我们又需要将这些异常值剔除掉来计算留存率,剔除的方法多种多样(大家可以参考Python 库Pyod的各种算法,在这个Kaggler 分享的PDF中有各种详细算法:https://www.kaggle.com/getting-started/104950)。在剔除异常数据的情况下,无论采用第一种算法或者第二种算法,差别并不大,对于业务的价值是差不多的,如下图所示。嗯,这下问题可以稍作终结了。

然而,关于留存的探讨并没有到此为止, 搞清楚留存计算后,作为一名优秀的数据分析师,既要知道留存数据怎么算,也要知道留存数据怎么用的问题。
02
留存怎么用
搞清留存计算之后,我们问一下,为什么要看留存?千万不要觉得这是产品经理的事情,数据分析师们只有明白了为什么,才能更好的提供准确可靠的数据。留存的用处之一是通过留存率和其他要素的情况下,预估公司收益(这也是数据分析师在面试时经常遇到的问题),但留存数据的用处可远不止于此。
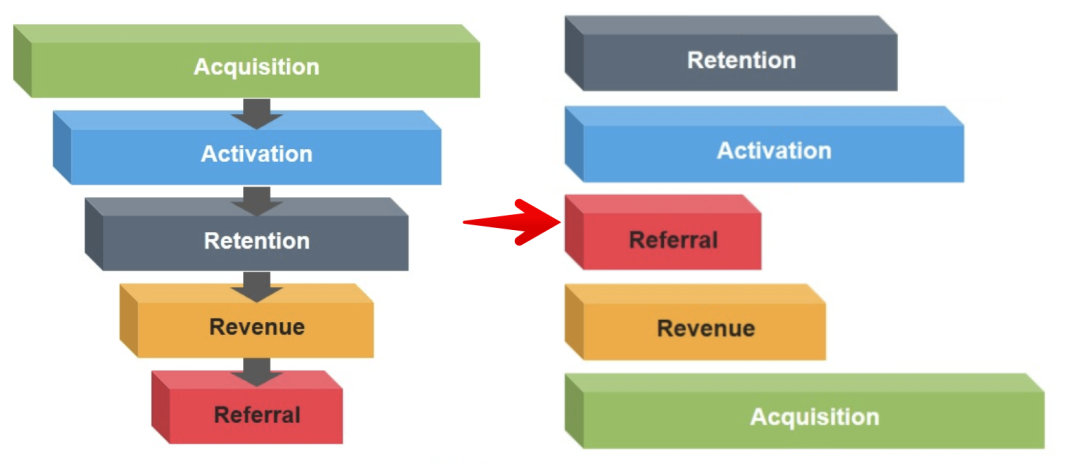
笔者曾经在一篇文章里看到这样一句话 “Without retention, your product is a leaky bucket”,翻译过来是“没有留存,犹如竹篮打水一场空” (或者翻译更形象一点,“没有留存,你的推广就是个无底洞”),好不容易拉新的客户,全部又流出去了。而在互联网下半场的浪潮里,另外一种增长黑客模型早已经浮出水面,即由AARRR 模型转变为RARRA,如下图所示,在RARRA模型中,留存--Retention 首当其冲,即先实现留存,再去做产品推广,让产品自己去运营,实现获客。
张小龙的[微信十年]相信不少人看过,演讲中所提的:“这是一种典型的微信style的产品方法,即通过产品而非运营的方法,找到事情的撬动点,通过产品能力让事情运转起来” 和RARRA的理念高度一致。我们今天就蹭一下热点,用留存的框架“套路”一下微信视频号的成长过程,纯属学习视角的讨论,欢迎大家拍砖留言。
个人认为RARRA增长模型下,产品成长过程中有以下几个阶段,而留存在是这几个阶段都需要关注的指标之一:
找到Market Fit,这个阶段留存分析能帮助产品发现“生存能力”。
培养初期留存用户的使用习惯,持续优化核心功能,这个阶段留存分析能帮助产品发现“基本能力”。
让更多的人看到核心功能,使产品被更广泛的人使用,这个阶段留存分析能帮助产品发现“价值能力”。
详细展开来说一下:
阶段1:找到Market Fit(即产品与市场的契合点),这个阶段留存分析能帮助产品发现“生存能力”。
微信视频号找到Market Fit 的过程是这样的,“以下摘自张小龙《微信十年》原文”。
“可能在2017年吧...但后来就不了了之了...
第一个版本其实只是搭建了这样一个ID体系,但这样的效果并不好...
但头几个月的滚动特别困难,似乎陷入了死结…
(2020年)5月份的时候,我们做了视频号最重大的一个改变...于是五月份发布了基于朋友点赞的新的灰度版本,终于看到了上扬的数据,用户的留存非常高。”
不知道大家看到这个过程是什么感受,我在想,作为业界“顶级产品的顶级产品经理”,都经历了如此多的曲折来尝试新事物,我们又有什么理由不去承担风险,快速试错呢?
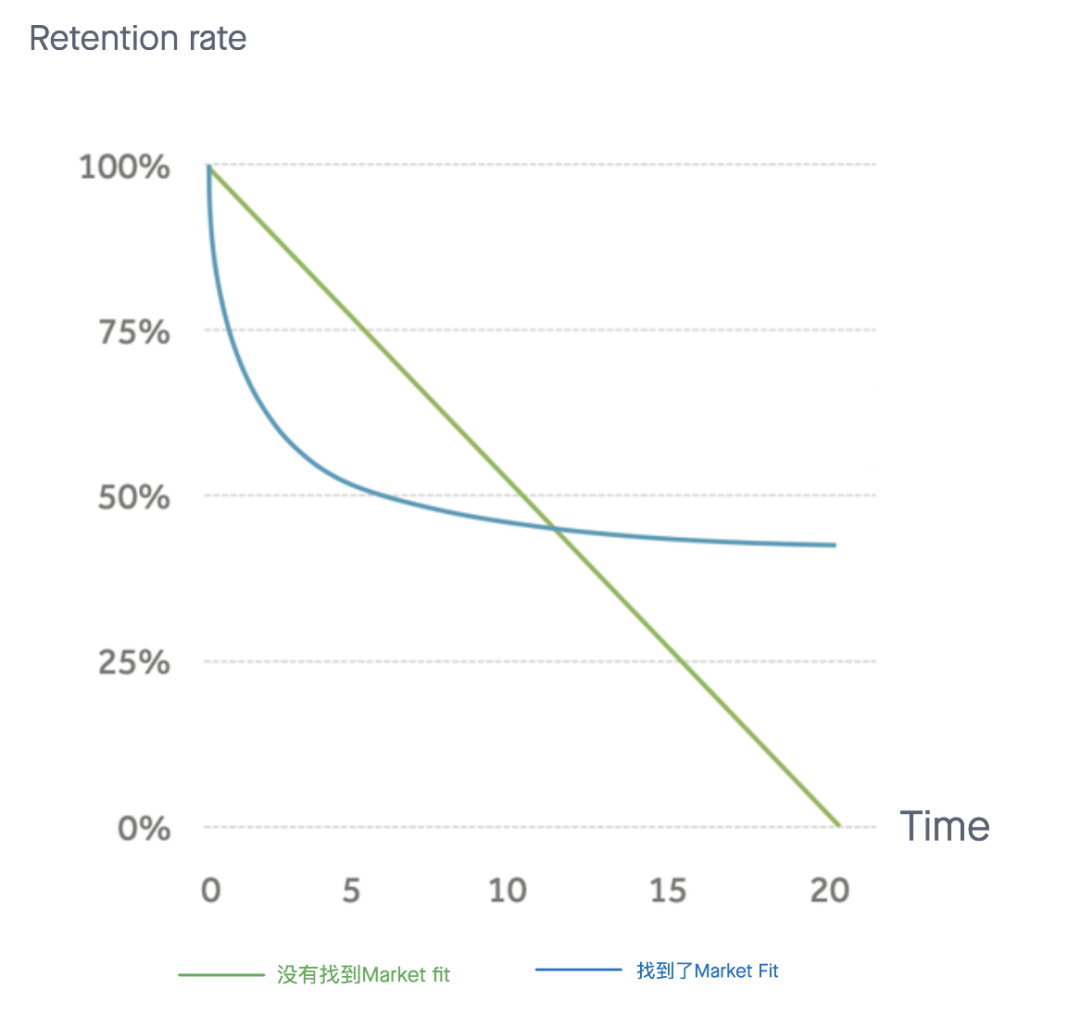
那么龙哥所提到的“上扬的数据”是什么呢?什么样的留存曲线算是找到了Market Fit, 如下图所示,绿色代表没有找到Market fit 的留存曲线,蓝色代表找了market fit 的曲线,显示出“上扬”的趋势。当然这个过程并非像这条曲线这样简单,只是为了学习,我将这个曲线做了简化处理。
阶段2:培养初期留存用户的使用习惯,持续优化核心功能,这个阶段留存分析能帮助产品发现“基本能力”。
“以下仍然摘自张小龙《微信十年》原文”。
“所以6月视频号的用户到了一个量级。数字其实不重要,但对于一个内容形态的产品来说,一定量级的用户意味着解决了生死问题,即流量的循环起来了... 有这个用户基数说明生存下来了,这时候就可以开始做基础功能的完善了,比如直播能力等。没有过生死线的话,做再多功能也是白搭。”
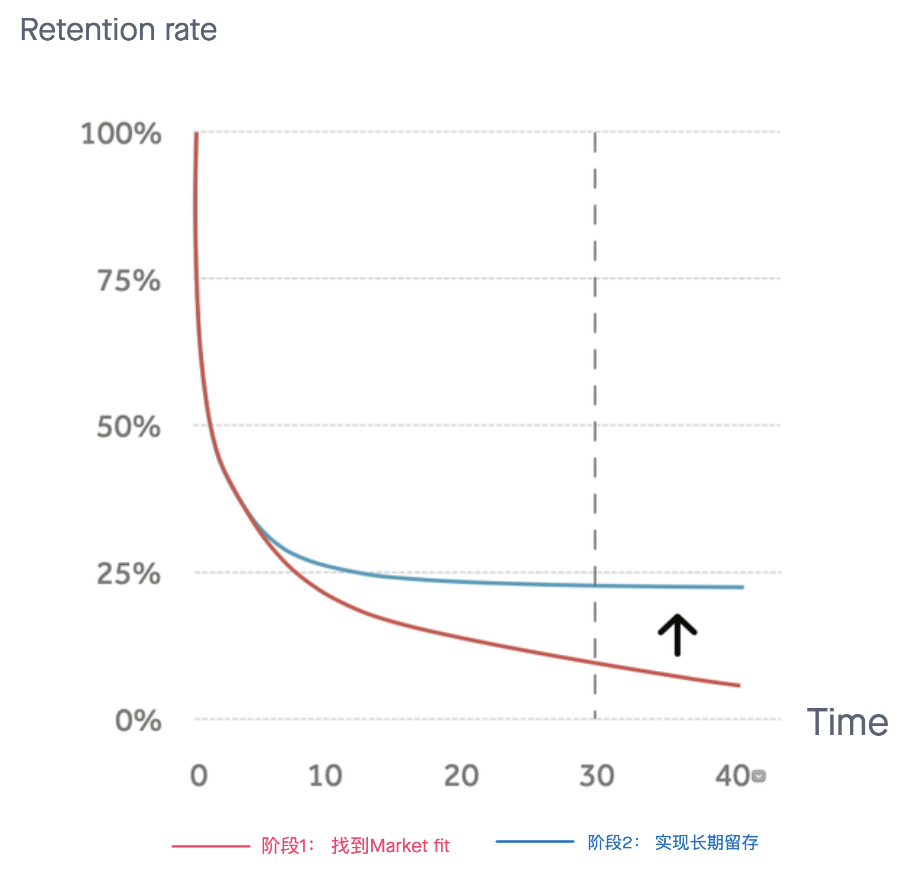
注意到没有:“一个量级..数字其实不重要..做基础功能的完善”,意味着在阶段1解决生存问题之后,数字的增长并没有作为重点来看,而是开始做“基础功能的完善”。即在第二个阶段,就是要不断刺激这部分用户持续使用,黏住他们,从而得到长期的留存,所以你看到的简化后的留存曲线的变化可能是这样:
阶段3: 让更多的人看到核心功能,使产品被更广泛的人使用,这个阶段留存分析能帮助产品发现“价值能力”。
这里谈一点我对微信视频号的观察,目前在我周围的人群中,微信视频号的用户占比不算太高,大部分人仍然觉得视频号是像抖音一样是杀时间的机器(目前的确也是)。原谅我周围的人都比较勤奋,不是“围观群众”,不愿意将时间花在消遣类的社交上 。但同时我也看到越来越多的高管、精英人士、原来写公众号的,开始做微信视频号了,趋势是好的。所以,个人感觉微信视频号目前仍然这个阶段3。至于微信视频号能否走好阶段3,未来拭目以待。
那么,在产品的这个阶段,如何利用留存分析帮助产品发现“价值能力”呢?我们大体可以把用户分为新用户、已有用户、已流失用户来分析。
新用户的留存分析:找到能让新用户再次回来的事件(从阶段2中挖掘),利用这个事件改进产品的第一印象,从留存曲线上来说,新用户的留存曲线的变化更倾向于下图这种。当然为了夸大第一印象的作用,我们把这个留存曲线简化了很多。
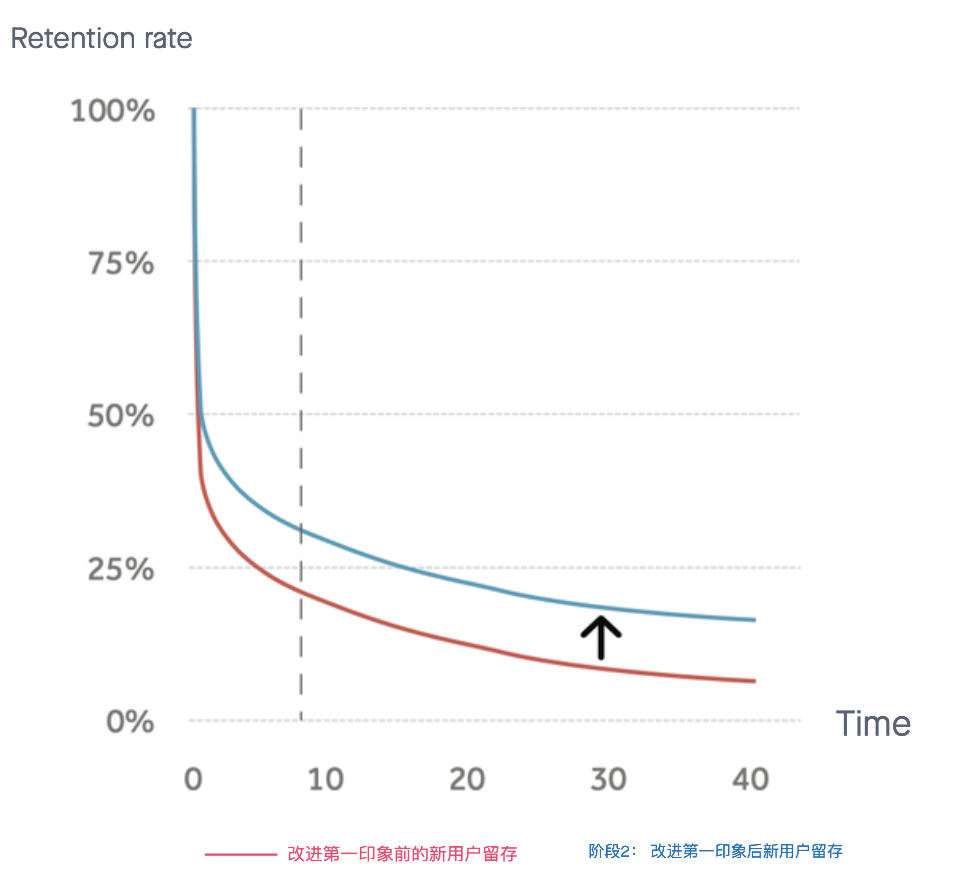
已有用户的留存分析:可能有些人说,已有用户是不是意味着已经留存下来,就不需要做留存分析了。恰恰相反,这部分用户的留存分析最能体现出产品的核心价值,即利用已有用户的行为痕迹帮助我们理解“产品能给用户带来什么价值”。
拿视频内容产品来举例,使用者可能是希望用视频做品牌宣传,可能是为了找到自己的圈子学习专业领域知识,也可能是为了好玩,可能还有一些我们也看不到的价值。我们按照行为我们把视频内容产品的用户粗略分成两大类(其实还可以细分),创作者和观赏者。针对两类角色我们需要定义不同的留存标准:
1.创作者的留存定义可能是这样的:
留存初始行为是发布视频
留存后续行为是发布视频
时间频率是每周,或者是其他定制化天数
即距离上一次发视频不超过一周(或者是其他定制化天数)又发了一次视频的用户为创作者的留存。
2. 对于观赏者的留存定义可以是这样的:
留存初始行为是观看视频
留存后续行为是观看视频
时间频率是每天,或者是其他定制化天数
即距离上一次看视频不超过1天(或者是其他定制化天数)又看了一次视频的用户为观赏者的留存。
你看到的简化后的留存曲线可能是这样的:

通过对不同行为群体进行留存分析是对产品细分价值的判断,我们可以帮助产品构建出一个健康的增长引擎。
已流失用户的留存分析:
为什么流失的客户还需要留存?
因为我们需要把老客户拉回来。
有研究表明重新激活老客户实际上比获新客成本更低。
这些用户可能是你在第一阶段获取的用户,因为彼时产品对他们来说价值不大,但到了第三阶段,或许到了一个赢回他们的好时机:
适宜地组织老客户拉回活动,告诉他们最近产品的变化(而不是骚扰式的push), 是不是会更有效。
在做这样一些活动时,我们同样需要观察客户重新拉回的留存率,用于评判产品的变化是否具备拉回“已流失用户”的能力。
把时间拉长,这部分的留存曲线甚至可能是呈现“微笑型曲线”。
当然上述的留存分析在产品不同阶段的应用并不是一概而论的,只能说在不同的阶段,我们的留存分析有不同的侧重。不变的一点是“留存分析” 在产品的全生命周期都扮演着非常重要的角色,尤其是在当下互联网产品百花齐放的时代,留存显得尤为重要。
03
总结
留存是当下互联网产品重要的评价指标,也是当前形势下增长黑客模型的第一要素。本文从两个角度对留存分析进行讨论:
留存怎么算,我们需要提供一个准确的留存率分析报告,这更多是数据分析师的职责。
留存怎么用,如何运用留存分析来推进产品迭代,以实现产品增长,这更多是产品经理的职责,但是作为数据分析师,理解数据的运用也同样重要。
当然,本文是抛砖引玉,欢迎各位数据分析师、产品经理、数据产品经理一起探讨,若有错误不吝指正。我们下回见。

一个数据人的自留地是一个助力数据人成长的大家庭,帮助对数据感兴趣的伙伴们明确学习方向、精准提升技能。
扫码关注我,带你探索数据的神奇奥秘



发表评论 取消回复