
哈喽,大家好,我是怪力少女赵壮实。
很高兴和大家又一次相聚在周六的早上~在上节《壮实学数据技术04:ETL》中,我们讨论了数仓开发,今天我们衔接一下,讲讲数据加工处理、数据报表生产必不可少的一环:数据调度。
01 什么是数据调度?
job和task有几种不同语境下的区别:
spark语境下
在 Spark 中, task 是一个 Job 进行切割后运行的最小运算单元。一般情况下, 一个 rdd 有多少个 partition,就会有多少个 task,因为每一个 task 只是处理一个 partition 上的数据。而 task 进行组合分批后, 被称为 stage。Spark 会为不同的 stage 以及不同的 task设好前后依赖,来保证整个 job 运行的正确性和完整性,最后一个resultTask 结束意味着 job 成功运行。
job>stage>task
hadoop语境下
Hadoop一个作业称为一个Job,Job里面分为Map Task和Reduce Task阶段,每个Task都在自己的进程中运行,当Task结束时,进程也会随之结束;
job>task
某调度产品语境下
Task:一个任务。
TaskType: 任务类型,如 ETL、MR job、 Simple。
Job:作业,任务在运行过程中的一次执行。
综上所述,job、task不同语境下,他们的关系是不一样的,所以在不同的数据调度产品中,要注意他们的区别。
我们来总结一下,数据调度,就是一个任务何时运行,何时结束以及正确的处理任务之间的依赖关系。我们需要关注的首要重点是在正确的时间点启动正确的作业,确保作业按照正确的依赖关系及时准确的执行。
02 数据调度产品包含什么模块?
在设计调度产品中,我们在其中需要理解几个问题:
1.触发机制:时间、依赖、混合
·时间 即任务按时间进行调度(年/月/日/小时/分钟/秒/毫秒)
·依赖 即任务按依赖关系进行调度
·混合 两者相互进行调度
2.工作流:任务状态(中断&运行)、任务管理or治理(类型、变更)、任务类型、任务分片。
3.调度策略:就绪&超时;重试&重试次数&重试用时。
4.任务隔离:任务和执行的关系等。
目前,市面上的任务调度系统有oozie、azkaban、airflow等等,此外,还有包括阿里的TBSchedule、腾讯的Lhotse、当当的elastic-job。
我们可以按dag工作流类、定时分片系统分为两类:
一种是dag工作流类系统:oozie、azkaban、chronos、lhotse
一种是分片类系统:TB Schedule、elastic-job、saturn
其中,dag ( Directed Acyclic Graph),就是一种向无环图,是指任意一条边有方向,且不存在环路的图。有个灵魂画手,我借鉴过来,我们可以感受一下什么是“有向无环”。

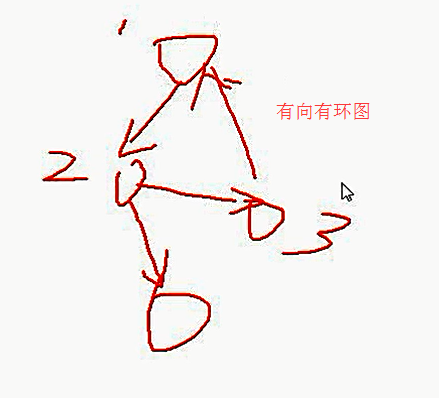
如果选择了dag工作流这种方式,我们就要注意时间、完成度,保证丰富灵活的触发机制。
分片是啥?我们来举个例子:如果我们有 3 台物理机,有 10 个每 5s 执行一次的定时



发表评论 取消回复