数据分析师翠花:
“老曹,今天的数据又没有产出,咋回事啊?我还忙着写分析报告呢!!!”
数据产品经理老曹:
“呃...你等等,我和数据开发工程师大熊一起看看。”

于是,老曹急忙跑到数据开发工程师大熊身边,气喘吁吁的说:
“大熊,今天数据的pipeline是不是又挂掉了啊?”
数据开发工程师大熊一脸迷茫的看着老曹,胆怯的说到:
“我也不知道啊,我手动查查看吧。”
数据产品经理老曹有点暴躁了,一脸问号的说:
“数据没有产出或者有问题,你们都不做报警的吗?”

数据开发工程师大熊低下了头,一言不语。
老曹有点忍不了了,拖过来一个画板,开始给大熊科普下数据治理应该怎么搞。
“产品千万种,数据第一条,建设不规范,公司两行泪。
作为一个在大数据领域工作多年的数据产品经理,我觉得数据中特别重要的就是数据质量,随着业务发展,数据量呈爆炸式增加,数据发挥的价值越来越大,数据质量问题也变得越来越严重,低质量的数据不仅使用不便,还会误导决策,甚至灾难性的结果,数据质量的好坏,决定了数据是否能够真正发挥价值。”
数据开发工程师大熊低着头说:
“你说的这些,我都懂,但是总感觉数据质量有点虚,应该从哪些方面来衡量它呢?”

老曹接着往下说:
“是的,那么如何判断数据质量的高低呢?什么样的数据是高质量的呢?引用美国著名的质量管理学家朱兰博士(J.M.Juran)的一句话:If they are fit for their intended in operations, decision making and planning.翻译一下,就是,如果根据这些数据做出的操作、决策和规划,符合之前的预期,那么这些数据就是高质量的,换个角度来理解,高质量的数据可以真实反映它们所代表的主体信息。
结合大数据与业务经验,在从定性的角度来看,影响数据质量的因素包括数据完整性、数据正确性、数据一致性、数据的可获取性以及数据的时效性等方面,其中,数据的完整性是指业务涉及到数据是完整的,能够对业务使用影响很大的数据都要保持一定的完整性;数据的正确性要满足准确性和精准性两方面,即数据要是准确无误的,数据要在精度上满足业务需求;数据的一致性要满足同一个指标的口径要一致,数据不要有二义性;数据的可获取性是指使用数据的时候,数据是被有效组织的,并且能够被高效获取;数据的时效性指使用的业务数据都是最新的,而不是无效的过期数据。”

数据开发工程师大熊越听越有兴趣,抬起头说:
“我们程序员都比较关注架构和具体实现,有没有一些架构和方案可以分享下啊?”
数据产品经理老曹点点头,觉得能够起到一定效果了,抓紧跟他说:
“影响数据质量的因素又有很多,包括数据埋点质量、数据传输过程中出现的问题,数据口径是否一致等等,因此,为了保证数据质量,有资源和精力的公司会搭建自己的数据管理系统,这个图就是数据管理中心产品架构,主要包含指标体系管理、全局数据管理、元数据管理等。另外,在数据安全性的前提下,还可以通过全局数据接口对外输出高质量的数据。”
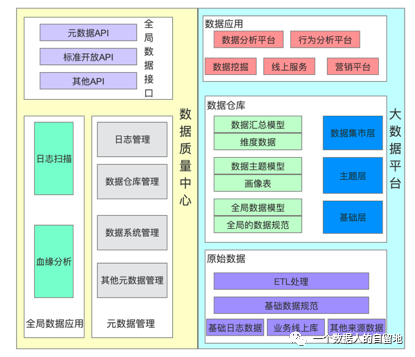
边说老曹边画了一个数据管理中心的产品架构图。然后接着给大熊讲到:
“以数据管理系统为例,它侧重于从时效性和数据一致性这两大质量方向保证数据的可读性。
首先,要做数据仓库的数据时效性检查。
明确每天的每一个层级、每一个数据表的最早和最晚生成时间,发现影响当天数据生成延误的数据表,并能够通过数据管理系统回答以下问题:
当天 MySQL 表和 Hive 表中的核心指标是何时生成的? 有哪些表的产出时间比预期时间延迟了? 任务延迟的原因是由哪几张表造成的? 瓶颈在哪里?优化哪几层?哪几张表可以提高核心指标等的生成时间?”
大熊一听,赶紧问道:
”这个是不是要给我打KPI啊,如果我的任务延迟会不会给我扣工资啊?“

数据产品经理老曹赶紧补充说:
”你想多啦,我给你画一下这个原型,你就知道拉,他的目的是了解任务的延迟情况,然后还能为以后的复盘使用,不是为了就揪小辫子啊!“
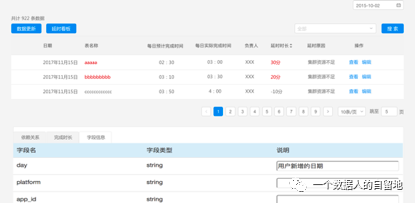
数据产品经理老曹接着说:
”然后,就是要做数据仓库的数据一致性检查。
通过数据一致性检查,在数据质量视图的展现下,我们可以快速了解存在依赖关系的数据表的分维度数据变化情况。
为了对数据一致性进行检查,大数据管理系统项目需要做的事情主要分为以下几步:
第一步,建立数据依赖引擎,实现依赖图谱。依赖图谱用于构建数据仓库表之间的分层级依赖关系,然后存入MySQL表并能支持可视化展现。
第二步,计算数据准备情况。各个表、各个分区的数据准备就绪时间按天、小时级进行汇总。根据Hive仓库的Meta信息可以获取Hive表各个分区的创建时间,根据创建时间确定数据的实效性,用来分析展现每天、每小时的状态和瓶颈。如果需要对MySQL进行验证,则通过SQL语句查询的方式获取对应时间在MySQL中是否存在。
第三步,建立数据计算引擎。根据定义的小时级指标、天级别指标规则,结合数据表各个分区的准备就绪时间,调用Spark SQL计算核心指标。
第四步,数据比较引擎。根据表和表之间核心指标的关系、表和表之间的规则进行比较验证。例如,A = B,A + B = C,B/A < 0.95等逻辑判断。”
大熊仿佛懂了很多,补充说:
”这里是不是可以有数据的血缘管理来展示?“

老曹表示认同的点点头,竖起来大拇指。
”是的,数据的血缘管理可以用来很形象的展现数据表之间的依赖关系,这只是一种展现方式,最重要的还是要根据比较引擎,找出数据异常的任务,然后给你及时发异常通知啊!”
大熊挠挠头,不好意思的说到:
“是啊,还需要及时提醒我数据有问题,要不我根本感知不到,现在睡觉都害怕。有这个系统就方便多了,还能快速帮助我定位问题,简直就是数据开发工程师的福利啊,咱们啥时候搞一个啊”

数据产品经理老曹看大家已经意识了数据质量管理平台的价值,补充道:
“当然是越快越好了,提升了数据质量,这样你就有更多的时间约妹子出去吃饭啦!”
大熊脸一红:
“你这么一说人家怪不好意思的,不过说的很对,赶紧搞起来吧!”

后续,公众号“一个数据人的自留地”会持续更新老曹入职公司后,作为数据产品经理的工作过程中的经历和心得,希望对各位有所帮助和启发,如果有共鸣,也欢迎大家留言、投稿,让“一个数据人的自留地”,成为一个有温度的数据社区。

一个数据人的自留地是一个助力数据人成长的大家庭,帮助对数据感兴趣的伙伴们明确学习方向、精准提升技能。
扫码关注我,带你探索数据的神奇奥秘





发表评论 取消回复