在进行数据分析之前,一般都会先想一下分析框架和分析方法,数据分析方法一般有常规分析、统计模型分析以及自建模型分析。掌握这三种分析思路,就能解决大部分分析需求,并根据分析需求固化为数据产品。下面重点讲一下这三个分析方法。
常规分析
其实很多公司80%的分析需求都是可以通过常规分析解决,很多分析师一般把业务相关数据从hive或者mysql中导入到excel,然后在excel中通过简单的表格、线图等方式来简单直观的分析数据。常规分析经常会用到同环比分析法和ABC分析法,即分析对比趋势和分析占比情况。
同环比分析应用到数据产品中常见的有业务周、月、日报等,例如,拿很多互联网公司都关注的核心指标DAU(日活跃用户数),周报里一般都会对比DAU的周环比变化,如果上涨或者下跌的比较大的话,就要进一步查找分析业务原因。
同比:某个周期的时段与上一个周期的相同时段比较,如今年的6月比去年的月,本周的周一比上周的周一等等。同比增长率=(本期数-同期数)/同期数×100%。
环比:某个时段与其上一个时长相等的时段做比较,比如本周环比上周等等。环比增长率=(本期数-上期数)/上期数×100%。
至于ABC分析法,一般是以某一指标为对象,进行数量分析,以该指标各维度数据与总体数据的比重为依据,按照比例大小顺序排列,并按照一定的比重或累计比重标准,将各组成部分分为ABC三类。举一个通俗易懂的例子,经过长期的观察发现:美国80%的人只掌握了20%的财产,而另外20%的人却掌握了全国80%的财产,而且很多事情都符合该规律。于是可以应用此规律在业务上,通过合理分配时间和力量到A类-总数中的少数部分,将会得到更好的结果。当然忽视B类和C类也是危险的,但是它确实得到与A类相对少得多的注意。
举一个比较简单的例子,在分析支付订单量的数据中,对各个城市的支付订单量做ABC分析法进一步分析,如图1所示,发现武汉、杭州、上海等地的支付订单量占比很大,这样就可以在运营活动中进一步关注占比比较高的城市,重点支持下这部分城市的活动推广。
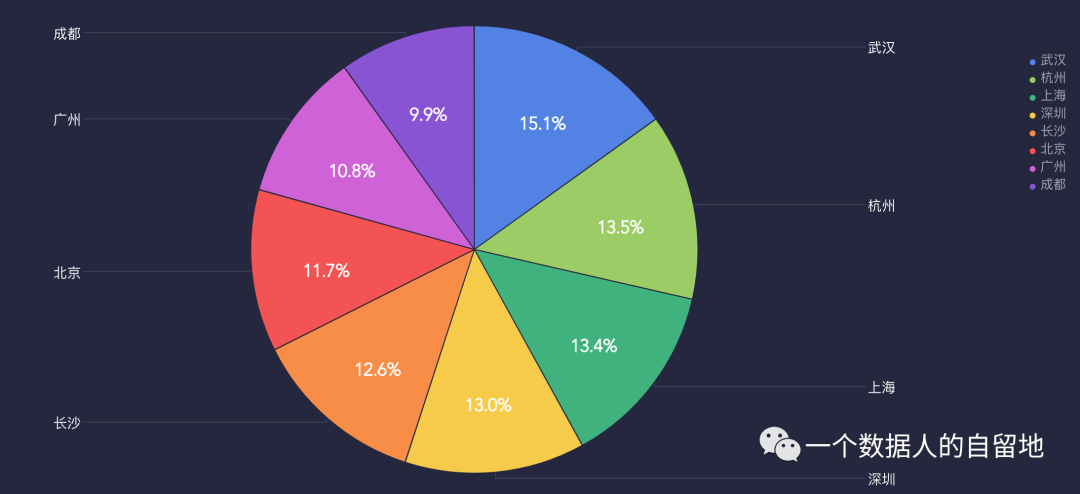
图1 各城市支付订单量占比情况
统计模型分析
当掌握了很大的数据量,希望在数据中挖掘出更多信息的时候,一般都可以应用成熟的模型进行比较深入的分析,例如,经常会面对如下的业务场景:
预测产品在未来一年内的日活用户数会按什么趋势发展,预估DAU;
上线了某个营销活动,预估活动效果怎么样,用户参与度情况;
对现有用户进行细分,到底哪一类用户才是目标用户群;
一些用户购买了很多商品后,哪些商品同时被购买的几率高。
针对于第一个案例,要用到回归分析,可以理解成几个自变量通过加减乘除或者比较复杂的运算得出因变量,例如预估DAU,因变量是DAU,和他有关的自变量有新增用户、老用户、老用户留存、回流用户等,然后根据历史数据,通过回归分析拟合成一个函数,这样就可以根据未来可能的自变量,进一步得出因变量。现在常用的回归分析主要有线性和非线性回归、时间序列等。
举个简单的例子,通过之前的业务支付订单量要预测未来的订单量情况作参考,在排除其他因素干扰的情况下,可以通过简单的线性回归根据支付订单量的历史值,进一步拟合出未来90的支付订单量曲线情况,如下图2所示。
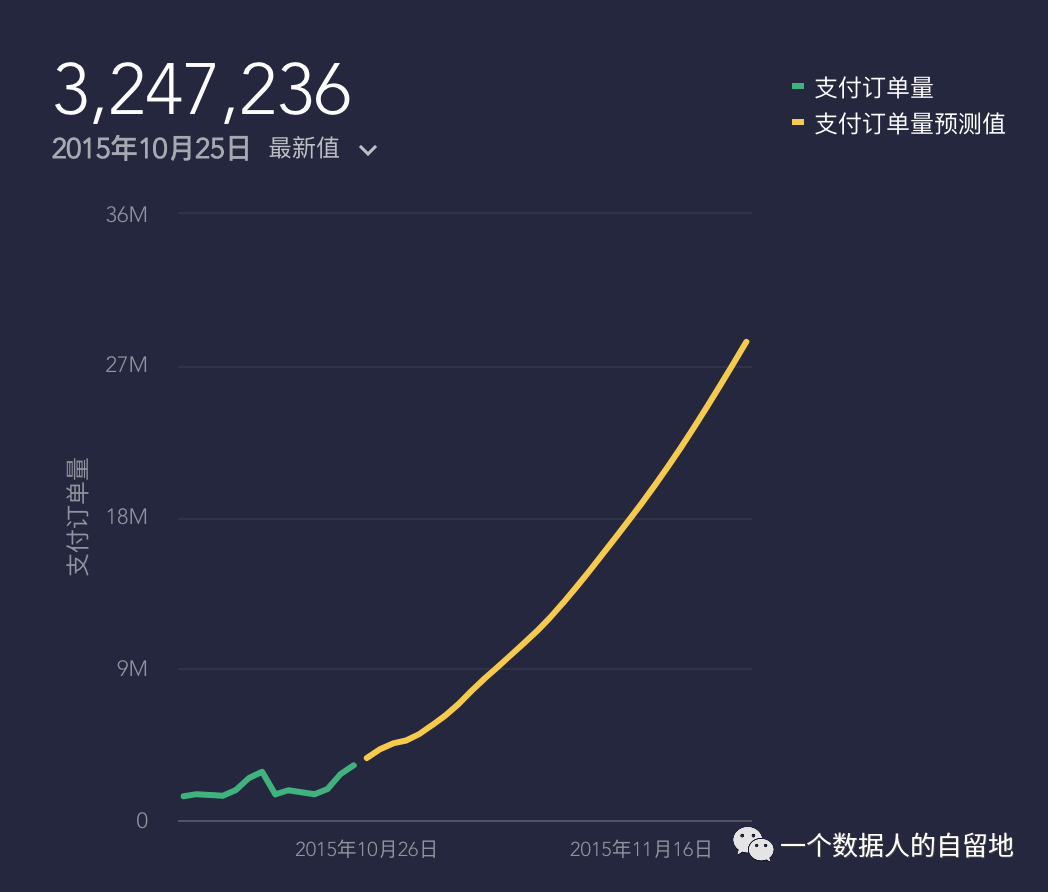
图2 线性回归预测支付订单量
针对第二个案列,根据以往活动的数据,分析活动的各个影响因素在满足什么情况时才会产生我们想要的效果,并可以根据有活动时和没有上线活动时的各项数据输入到系统中,这个函数就会根据判断活动效果会与哪些因素有关,目前常用的分类分析方法有:决策树、贝叶斯、KNN、神经网络等。
关于第三个案例,可以用聚类分析,细分市场、细分用户群里都属于聚类问题,这样更方便了解用户的具体特征,从而针对性的做一些营销等,常见的聚类分析一般有K均值聚类、分布估计聚类等。
关于聚类分析,最常用的就是对用户进行分类,首先,要选取聚类变量,要尽量使用对产品使用行为有影响的变量,但是还是要注意这些变量要在不同研究对象上有明显差异,这些变量之间又不存在高度相关,例如,年龄、性别、学历等。然后,把变量对应的数据输入到模型中,选择一个合适的分类数目,一般会选拐点附近的几个类别作为分类数目,如下图3。接下来,要观察各类别用户在各变量上的表现,找出不同类别用户区别去其他用户的重要特征,选取最明显的几个特征,最后进行聚类处理。
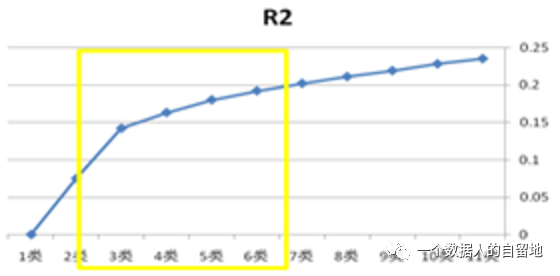
图3 R2曲线
关于第四个案例,要用到关联分析,在电商中的应用场景比较大,最经典的案例当属啤酒与尿不湿的搭配销售,常用的关联分析有购物篮分析、属性关联分析等。
做关联分析一般要理解频繁项集和关联规则两个概念,频繁项集是经常出现在一块儿的物品的集合,关联规则暗示两种物品之间可能存在很强的关系。
下面用一个例子来说明这两种概念:例如图4,给出了某个杂货店的交易清单。
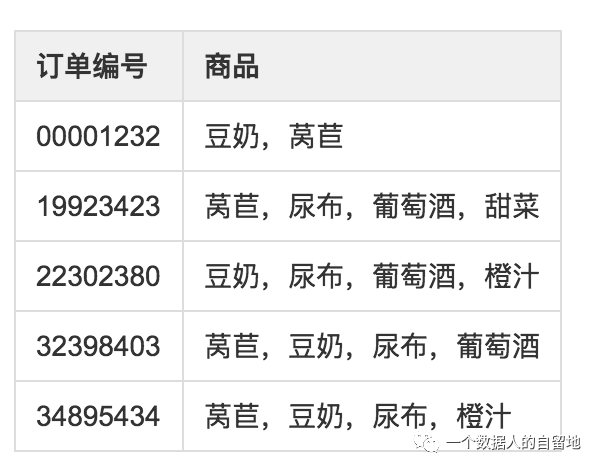
图4 订单交易情况
频繁项集是指那些经常出现在一起的商品集合,图中的集合{葡萄酒,尿布,豆奶}就是频繁项集的一个例子。从这个数据集中也可以找到诸如尿布->葡萄酒的关联规则,即如果有人买了尿布,那么他很可能也会买葡萄酒。
另外,为了评估关联分析的效果和可信性,定义了可信度或置信度这两个概念。规则{尿布}➞{啤酒}的可信度被定义为”支持度({尿布,啤酒})/支持度({尿布})”,由于{尿布,啤酒}的支持度为3/5,尿布的支持度为4/5,所以”尿布➞啤酒”的可信度为3/4。这意味着对于包含”尿布”的所有记录,我们的规则对其中75%的记录都适用。
自建模型分析
当以上两种分析方法都不能满足业务的分析需求时,这时候就需要自建模型进行分析,例如每个公司的业务模式都不太一样,当要分析用户在生命周期产生的价值(LTV)时,就需要根据自己的业务模式进行自建模型分析,对于一般依靠广告营收的公司,LTV会与用户活跃天数和Arpu(每用户平均收入)值有关,而Arpu值方面,每个公司都有自己的广告营收模式,所以Arpu值细分下去都是不太一样的。自建模型是为了满足业务需求,将各个指标灵活自由组合,从而保证分析的有效性和针对性。
具体来看,定义LTV=平均活跃天数Arpu值=平均活跃天数(指标1* 参数1 + 指标2* 参数2 + 指标3 * 参数3+……),其实,除了平均活跃天数需要预测外,后面的几个指标的值都比较明确,直接输入固定值就可以。
平均活跃天数预测方式:
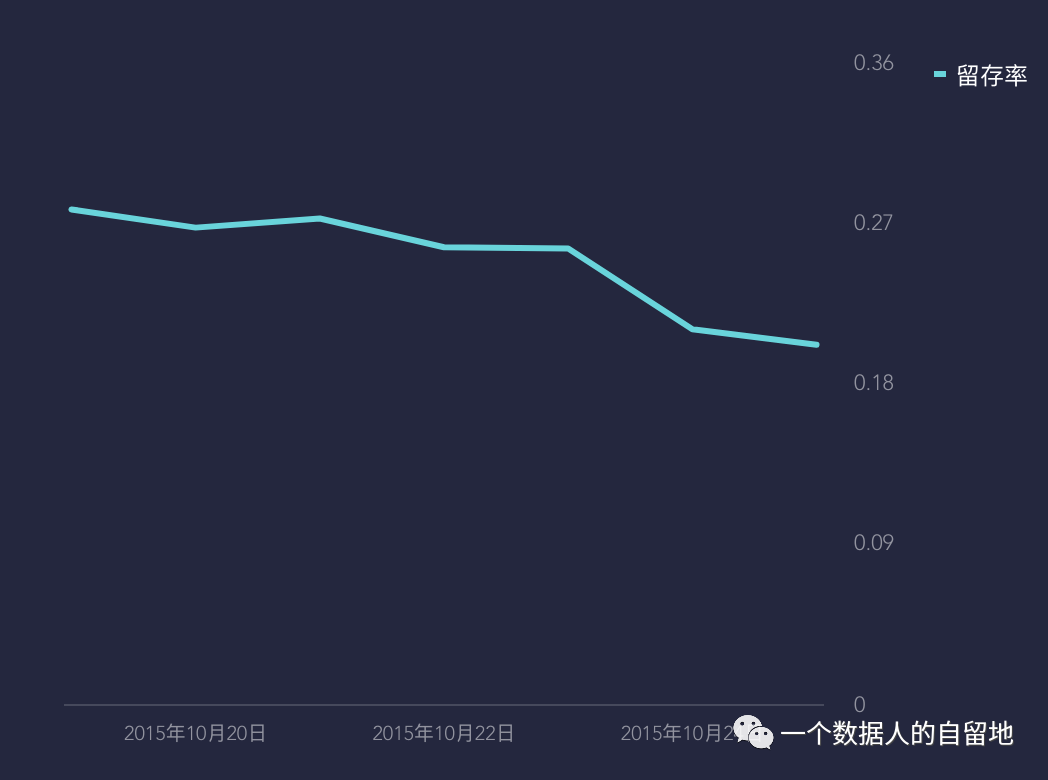
图5 留存率曲线
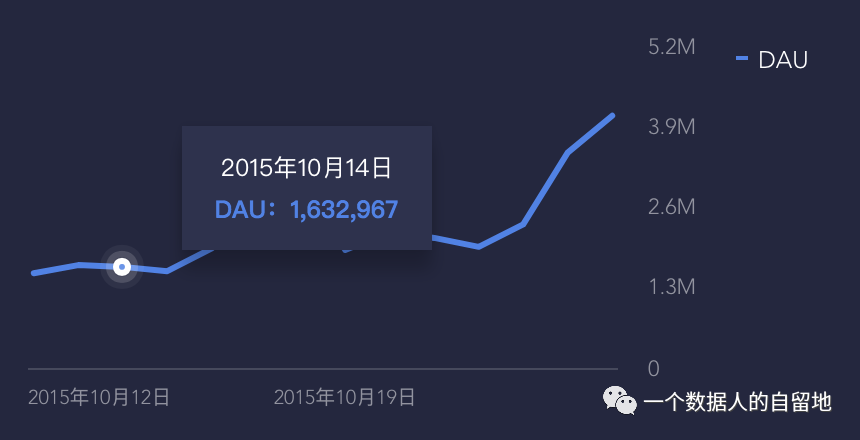
图6 DAU曲线
如上图5和6的所示根据实际留存率和实际ArpuDau进行截断天数内平均活跃天数预测:
(1)INPUT /每日实际留存数,OUTPUT/beta(α,β)曲线,预测哪一天就根据beta曲线返回对应值【预测非线性拟合,起始点和终点权重较大】
对beta曲线目前分为三个partition:
乐观预估:因ArpuDau持续上涨导致波动过大,输出值过大。
稳健预估:为保证输出值稳定平滑,进行log导数限制。
当前平均预估:在稳健预估无法输出有效值时采用此预估方法,根据当前留存和Arpu值作为重点,对未来进行预估。
(2)ArpuDau根据实际情况按公式进行每日计算,一段时间后Arpu值趋于稳定。
(3)LTV公式= ∑(留存beta1Arpu1+留存beta2Arpu2+….+留存betakArpuk),可简单理解为∑留存beta∑ArpuDau
k值由模型调用者决定,660天LTV预估同样可由模型调用者进行修改调整。
总结
其实,以上的分析方法和思路,数据产品经理只需要掌握基本的20%就能解决80%的问题,剩下的20%的问题,可以交给更专业的数据分析师们去解决,当然,多学一些分析方法,对以后的数据工作还是很有帮助的。毕竟,数据产品和数据分析是分不开的,都是基于数据需求解决一定问题出发的,选择什么方法去解决问题,还是需要具体深入到业务中去。





发表评论 取消回复