
作为一个数据菜鸟,我们总是会听到一些别人“习以为常”的黑话。例如,在数据仓库中,必不可少地要和表、数据打交道。但是一堆不知所云的“表”,总会让我们头大。

01 全量表\增量表\快照表
我们先从几个物理概念入手理解什么是流量、存量、增量
(1)存量:系统在某一时点时的所保有的数量;
(2)流量:是指在某一段时间内流入/流出系统的数量
(3)增量:则是指在某一段时间内系统中保有数量的变化情况,但是常规意义上就是增加的量,增量=流入量–流出量
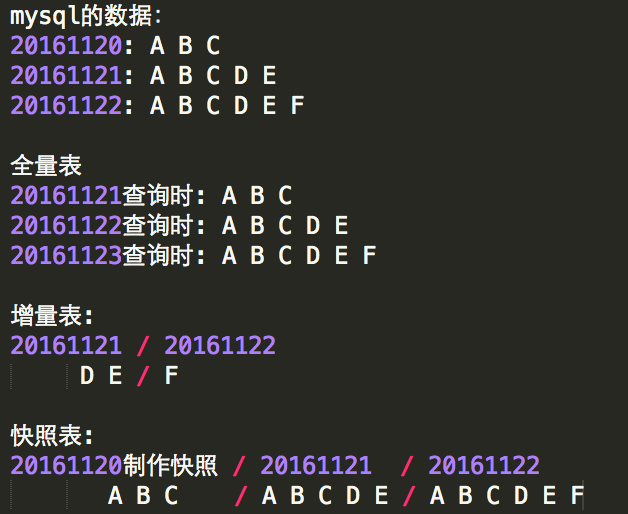
全量表
全量表无分区,每天凌晨流程执行完后,表中数据是截止到前一天的数据。以上图为例,20161121查询全量表数据,就是20161120的数据:ABC,以此类推。
增量表
增量表按天分区,分区字段为dt=YYYYMMDD, 每一天的分区会存放在那一天所产生的增量数据(insert, update的数据),注意目前增量表的同步方式不会包含历史数据,即只存放增量数据。以上图为例,我们最早可以在20161122查询20161121的增量表数据,为DE,即20161121比20161120多出来的数据。
快照表
快照表按天分区,分区字段为dt=YYYYMMDD, 每一天的数据都是截止到那一天的全量数据。以上图为例,我们最早可以在20161121查询20161120的快照数据,为ABC。
02 拉链表\流水表\中间表
拉链表
维护历史状态以及最新状态数据的一种表,拉链表根据拉链粒度的不同,可以方便的还原出拉链时点的操作记录。拉链表也是分区表,分区字段一般为start_date、end_date。如果我们想获取某一天全量的数据,可以通过表中的start_date和end_date来做筛选,选出固定某一天的数据。例如我想取截止到20201111的全量数据,其where过滤条件就是where start_date<='20201111' and="" end_date="">='20201111'。
拉链表和增量表的表结构基本一样。适用于表的数据量很大,表中的部分字段会被update更新操作,而我们需要查看某一个时间点或者时间段的历史快照信息,如统计账户及客户的情况。如果每天保留一份全量数据,就浪费了存储空间,有时可能业务统计也有点麻烦;如果保留一份最新的全量数据,就看不到数据的变化,所以拉链表是个很好的选择。
流水表
流水表:记录表的每一个修改,反映实际记录的变更。
流水表也为分区表流水表有多方面的作用,如记录与结算相关的金额信息,与结算侧的数据核对;流水有不同的状态:未就绪、已就绪、已发送,通过不同的状态,流水可以做不同的动作以流转到下一状态,达成最终通知结算的目的。

中间表
简单来说,中间表是数据库中专门存放中间计算结果的数据表。
第一种情况,计算sql计算无法一步到位,需要经过复杂的设计,要经过几个过度才能得到想要的结果。
第二种情况,实时计算所需要时间过长。或者因为数据量大或者因为计算太复杂,比如某一时间点前一段时间计算好结果,当到达改时间点使用中间表顶上。
第三种情况,当数据源比较多(通常情况),需要多表混合计算整合,这时导入数据库形成中间表是必要的。
03 宽表vs窄表
宽表:
从字面意义上讲就是字段比较多的数据库表。
通常是指业务主题相关的指标、维度、属性关联在一起的一张数据库表。由于把不同的内容都放在同一张表存储,宽表已经不符合三范式的模型设计规范,坏处就是数据冗余,好处是查询性能的提高与便捷。这种宽表的设计广泛应用于数据挖掘模型训练前的数据准备阶段,通过把相关字段放在同一张表中,可以大大提高数据挖掘模型训练过程中迭代计算时的效率问题。(一句话,空间换时间,便于训练迭代、减少表关联数量,修改少量数据时不需要该多张表。)
窄表:
严格按照数据库设计三范式。尽量减少数据冗余,但是缺点是修改一个数据可能需要修改多张表。
04 维度表vs事实表
事实表
每个数据仓库都包含一个或者多个事实数据表。事实表每行对应一个业务过程事件度量。包括数字度量和与维度表相关联的外键。
事实表分类
·事务事实表:对应现实中空间或时间上某点度量事件。仅当存在度量事件时才会插入行。一般是原子维度。(典型的销售表)日期,产品,地区,客户,数量;
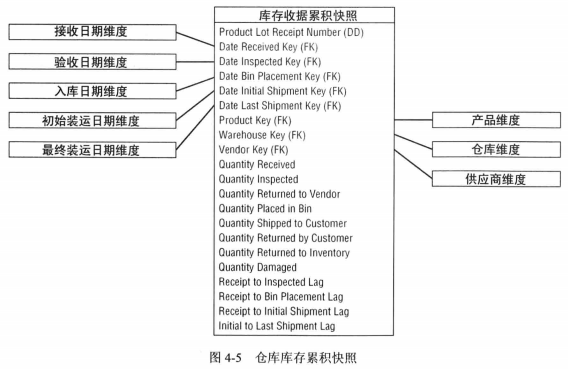
·周期快照事实表:每行汇总了发生在某一标准周期的多个度量事件,或者记录了快照时间点业务活动度量值,快照表能展现出更多重要的过程,与事务事实表互相补充。粒度是周期性的,密度是均匀的,即使周期内未发生活动,也会在表中每个事实插入0或空值或未发生变化的值的行。(典型的库存表)日期,产品,仓库,期初数量,期末数量。

·累计快照事实表:每行汇总了业务过程开始和结束之间已知步骤的度量事件,通常包含一个状态维度的外键,用于更新状态维度以反映当前行整个流程的最新状态。当业务过程开始时,会插入一行,当业务过程步骤发生状态变化时,会修改该行。(典型的送货表)产品,客户,下单时间,出库时间,签收时间。
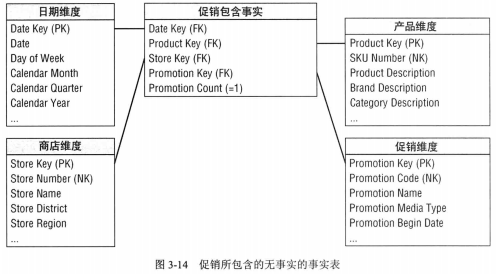
·无事实的事实表:无具体度量值,事件仅记录一系列某时刻发生的多维事实。如某天学生参加课程的事件,其中没有数值,但事件包含日期、学生、教师、地点等属性信息。或者通过每个周期记录每个促销产品形成促销事实表,再用该表跟销售事实表做差集,找到在促销但未发生销售事实的产品。用来关注什么未发生。一般是周期性的表。
·聚集事实表:是对原子粒度事实表数据进行简单的数字化上卷操作,目的是为提高查询性能。
·合并事实表:通常将来自多个业务过程的,以相同粒度表示的事实合并为一个单一的合并事实表。适合经常需要共同分析的多个业务过程度量。
维度表
维度表包含单一的主键列。例如,包含产品信息的维度表通常包含将产品分为食品、饮料、非消费品等若干类的层次结构。维度表包含了事实表中指定属性的相关详细信息,比如,详细的产品,客户属性,存储信息等。
维度表分类
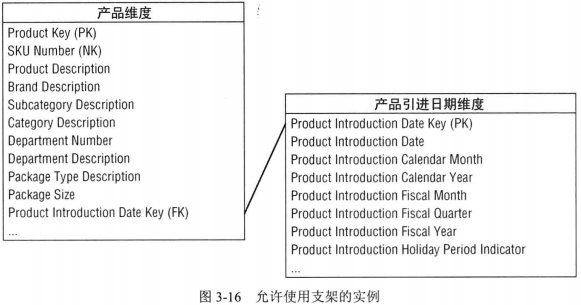
支架表
当维度表中存在以其他维度条件过滤、分组查询时,可以使用支架表实现。比如产品维度中的产品引进日期,如果需要通过非标准日历属性(如财务周期,假日周期等)过滤和分组查询时,就需要支架表来实现。如果没有这类查询,则只需要将引进日期字段使用普通的日期类型保存即可。
桥接表(多值维度)
在多值情况下,可以使用桥接表。
·事实与维度的多值关系:比如报销账单事实表粒度为一次体检,其对应的检查项维度会有多个。
·维度与维度的多值关系:例如用户帐户维度与消费自然人客户维度有多对多关系。因此在帐户维度表与自然人维度表中加入一个“帐户与客户关系”桥接表。
·可变层次展示:例如职员与职员间隶属关系,可以使用桥接表记录每个职员与其所有下属之间的隶属关系和其下属的直接上司,就可以层次化的表示出职员之间关系。
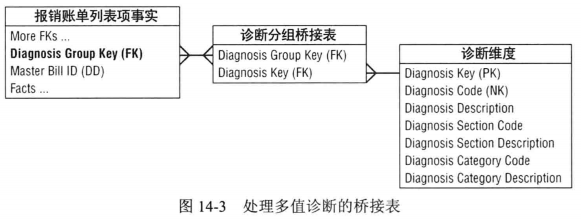
审计维度
数据仓库内部的维度表。包含了事实表变更的元数据,事实数据的加载时间,数据质量指标。审计维度可以提供如下的信息:
·审计信息:数据源、加载时间、加载过程、加载时所用的规则
·提供数据质量的指标和统计:读取了多少行记录,插入了多少行,拒绝了多少行。事实数据是否完整,事实表的值是否在有效区域内。
大表小表千千万,千言万语尽在不言中。
数据道路上道阻且长,数据人会一直在你身边哦~
我们下期见!下周六将与你分享《数据仓库模型设计那些事》。




发表评论 取消回复