知乎@王多鱼
京东的一名推荐算法攻城狮。
主要负责商品推荐的召回和排序模型的优化工作。
一、DSSM模型的原理简介
DSSM模型的全称是Deep Structured Semantic Model,由微软研究院开发,利用深度神经网络把文本(句子,Query(关键词),实体等)表示成向量,应用于文本相似度匹配场景下的一个算法。
DSSM模型在信息检索、文本排序、问答、图片描述、及机器翻译等中有广泛的应用。该模型是为了衡量搜索的关键词和被点击的文本标题之间的相关性。DSSM模型的原理比较简单,通过搜索引擎里Query和Document的海量的点击曝光日志,用DNN深度网络把Query和Document表达为低维语义向量,并通过余弦相似度来计算两个语义向量的距离,最终训练出语义相似度模型。该模型既可以用来预测两个句子的语义相似度,又可以获得某句子的低维语义Embedding向量。
DSSM模型的整体结构图如图1所示,Q代表Query信息,D表示Document信息。
(1)Term Vector:表示文本的Embedding向量;
(2)Word Hashing技术:为解决Term Vector太大问题,对bag-of-word向量降维;
(3)Multi-layer nonlinear projection:表示深度学习网络的
隐层;
其中:
Wi表示第i层的权值矩阵,bi表示第i层的bias项。
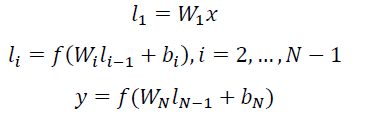
用tanh作为隐层和输出层的激活函数:
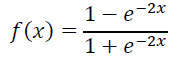
(4)Semantic feature:表示Query和Document 最终的
Embedding向量;
(5)Relevance measured by cosine similarity:表示计算
Query与Document之间的余弦相似度;即:
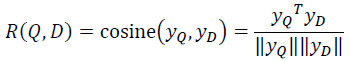
(6)Posterior probability computed by softmax:表示通过Softmax 函数把Query 与正样本Document的语义相似性转化为一个后验概率;即:
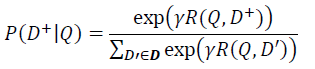
其中:
r为Softmax的平滑因子,D+为Query下的正样本,(D’- D+)为Query的随机采取的负样本,D为Query下的整个样本空间。在训练阶段,通过极大似然估计,最小化损失函数:
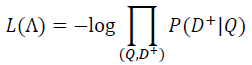
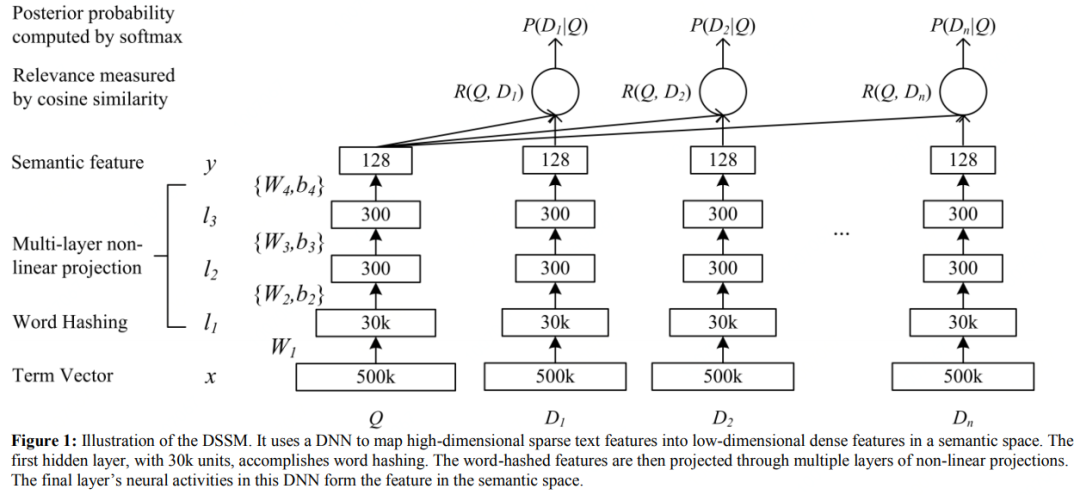
图1 DSSM模型的网络结构图
二、DSSM模型在推荐召回环节的应用
1.DSSM模型在推荐召回环节的结构
DSSM模型的最大特点就是Query和Document是两个独立的子网络,后来这一特色被移植到推荐算法的召回环节,即对用户端(User)和物品端(Item)分别构建独立的子网络塔式结构。该方式对工业界十分友好,两个子网络产生的Embedding向量可以独自获取及缓存。目前工业界流行的DSSM双塔网络结构如图2所示。
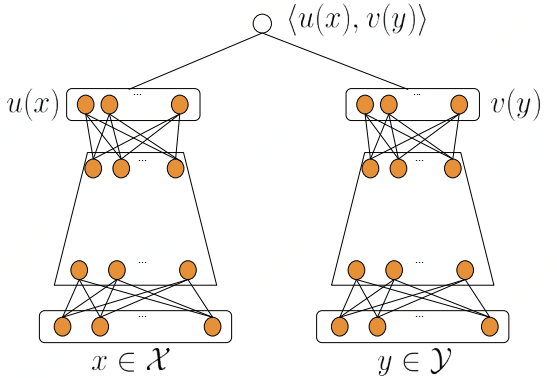
图2 工业界DSSM双塔模型结构图
双塔模型两侧分别对(用户,上下文)和(物品)进行建模,并在最后一层计算二者的内积。其中:
(1)x为(用户,上下文)的特征,y为(物品)的特征;
(2)u(x)表示(用户,上下文)最终的Embedding向量表示,v(y)表示(物品)最终的Embedding向量表示;
(3)<u(x), v(y)>表示(用户,上下文)和(物品)的余弦相似度。
2.候选集合召回
当模型训练完成时,物品的Embedding是可以保存成词表的,线上应用的时候只需要查找对应的Embedding即可。因此线上只需要计算 (用户,上下文) 一侧的Embedding,基于Annoy或Faiss技术索引得到用户偏好的候选集。
3.应用Trick
(1)对双塔两侧输出的Embedding进行L2标准化;
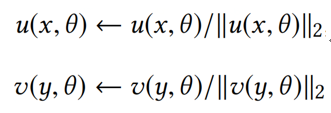
(2)对于内积计算的结果,除以一个固定的超参。
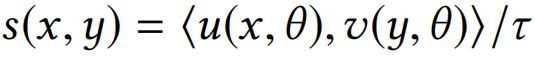
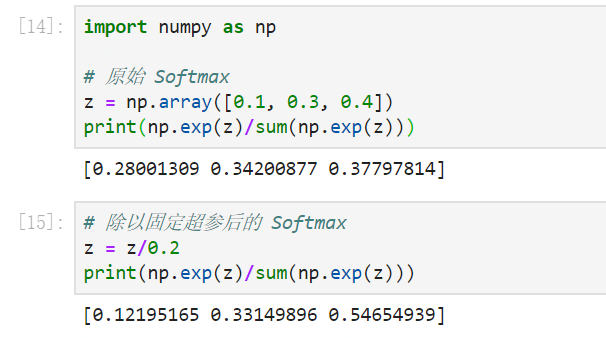
超参的设定可以通过实验结果的召回率或者精确率进行微调。除以超参的效果如下,可以看到Softmax的效果更加明显。
三、DSSM模型在推荐召回环节的实践
下面使用一个简单的数据集,实践一下DSSM召回模型。该模型的实现主要参考:python软件的DeepCtr和DeepMatch模块。
1. 数据处理
(1.1)加载数据
samples.txt 数据可以从百度网盘下载:
链接:
https://pan.baidu.com/share/init?surl=eM4q61tSrPLurQYxC29vbg
提取码: 1mjz
import pandas as pdfrom sklearn.utils import shufflefrom sklearn.model_selection import train_test_split
from keras.utils import plot_model
samples_data = pd.read_csv("samples.txt", sep="\t", header = None)samples_data.columns = ["user_id", "gender", "age", "hist_movie_id", "hist_len", "movie_id", "movie_type_id", "label"]
samples_data.head()
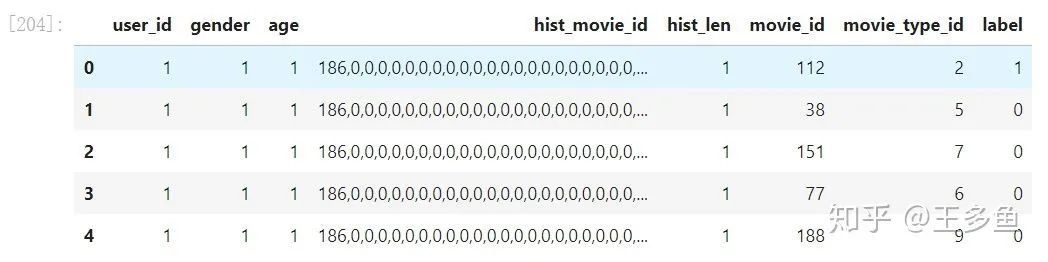
本示例中包含:7个特征。
user端特征有5个,分别为:
["user_id","gender","age","hist_movie_id","hist_len"];

movie端特征有2个,为 ["movie_id", "movie_type_id"];

(1.2)打乱数据集
samples_data = shuffle(samples_data)
X = samples_data[["user_id", "gender", "age", "hist_movie_id", "hist_len", "movie_id", "movie_type_id"]]y = samples_data["label"]
(1.3)转换数据存储格式
train_model_input = {"user_id": np.array(X["user_id"]), \ "gender": np.array(X["gender"]), \ "age": np.array(X["age"]), \ "hist_movie_id": np.array([[int(i) for i in l.split(',')] for l in X["hist_movie_id"]]), \ "hist_len": np.array(X["hist_len"]), \ "movie_id": np.array(X["movie_id"]), \ "movie_type_id": np.array(X["movie_type_id"])}
train_label = np.array(y)
2.构建模型
(2.1)统计每个离散特征的词频量,构造特征参数。
import pandas as pdfrom deepctr.inputs import SparseFeat, VarLenSparseFeatfrom sklearn.preprocessing import LabelEncoderfrom tensorflow.python.keras.models import Modelfrom deepmatch.models import *
embedding_dim = 32SEQ_LEN = 50user_feature_columns = [SparseFeat('user_id', max(samples_data["user_id"])+1, embedding_dim), SparseFeat("gender", max(samples_data["gender"])+1, embedding_dim), SparseFeat("age", max(samples_data["age"])+1, embedding_dim), VarLenSparseFeat(SparseFeat('hist_movie_id', max(samples_data["movie_id"])+1, embedding_dim, embedding_name="movie_id"), SEQ_LEN, 'mean', 'hist_len'), ]
item_feature_columns = [SparseFeat('movie_id', max(samples_data["movie_id"])+1, embedding_dim), SparseFeat('movie_type_id', max(samples_data["movie_type_id"])+1, embedding_dim)]
(2.2)构建模型
from deepctr.inputs import build_input_features, combined_dnn_input, create_embedding_matrixfrom deepctr.layers.core import PredictionLayer, DNNfrom tensorflow.python.keras.models import Modelfrom deepmatch.inputs import input_from_feature_columnsfrom deepmatch.layers.core import Similarity
def DSSM(user_feature_columns, item_feature_columns, user_dnn_hidden_units=(64, 32), item_dnn_hidden_units=(64, 32), dnn_activation='tanh', dnn_use_bn=False, l2_reg_dnn=0, l2_reg_embedding=1e-6, dnn_dropout=0, init_std=0.0001, seed=1024, metric='cos'):
embedding_matrix_dict = create_embedding_matrix(user_feature_columns + item_feature_columns, l2_reg_embedding, init_std, seed, seq_mask_zero=True)
user_features = build_input_features(user_feature_columns) user_inputs_list = list(user_features.values()) user_sparse_embedding_list, user_dense_value_list = input_from_feature_columns(user_features, user_feature_columns, l2_reg_embedding, init_std, seed, embedding_matrix_dict=embedding_matrix_dict) user_dnn_input = combined_dnn_input(user_sparse_embedding_list, user_dense_value_list)
item_features = build_input_features(item_feature_columns) item_inputs_list = list(item_features.values()) item_sparse_embedding_list, item_dense_value_list = input_from_feature_columns(item_features, item_feature_columns, l2_reg_embedding, init_std, seed, embedding_matrix_dict=embedding_matrix_dict) item_dnn_input = combined_dnn_input(item_sparse_embedding_list, item_dense_value_list)
user_dnn_out = DNN(user_dnn_hidden_units, dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed, )(user_dnn_input)
item_dnn_out = DNN(item_dnn_hidden_units, dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed)(item_dnn_input)
score = Similarity(type=metric)([user_dnn_out, item_dnn_out])
output = PredictionLayer("binary", False)(score)
model = Model(inputs=user_inputs_list + item_inputs_list, outputs=output)
model.__setattr__("user_input", user_inputs_list) model.__setattr__("item_input", item_inputs_list) model.__setattr__("user_embedding", user_dnn_out) model.__setattr__("item_embedding", item_dnn_out)
return model
(2.3)编译模型及训练模型
model = DSSM(user_feature_columns, item_feature_columns)model.compile(optimizer='adagrad', loss="binary_crossentropy", metrics=['accuracy'])
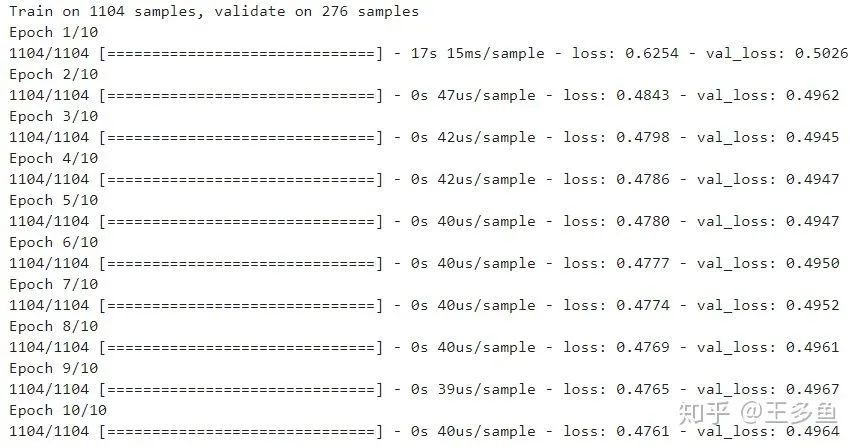
history = model.fit(train_model_input, train_label, batch_size=256, epochs=10, verbose=1, validation_split=0.2, )
训练过程如图所示:
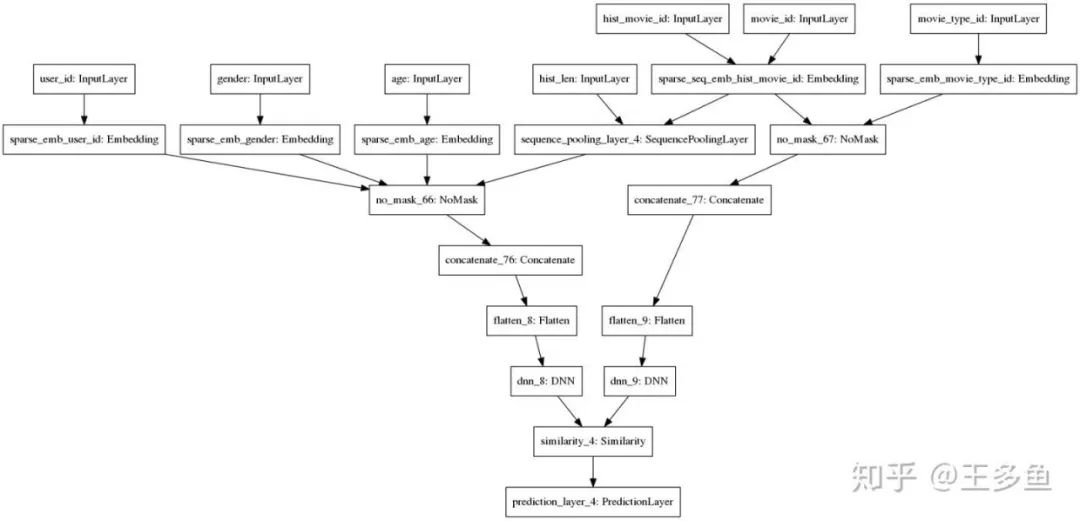
(2.4)打印看一下模型的结构
(2.5)画一下模型的loss值,看看模型收敛的情况。
import matplotlib.pyplot as plt loss = history.history['loss']val_loss = history.history['val_loss']epochs = range(1, len(loss) + 1)plt.figure()plt.plot(epochs, loss, 'bo', label='Training loss')plt.plot(epochs, val_loss, 'b', label='Validation loss')plt.title('Training and validation loss')plt.legend()print(plt.show())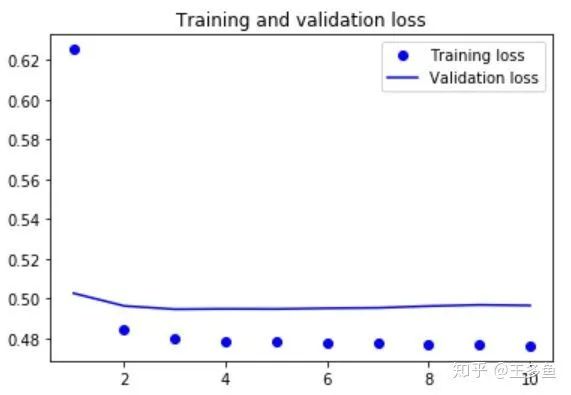
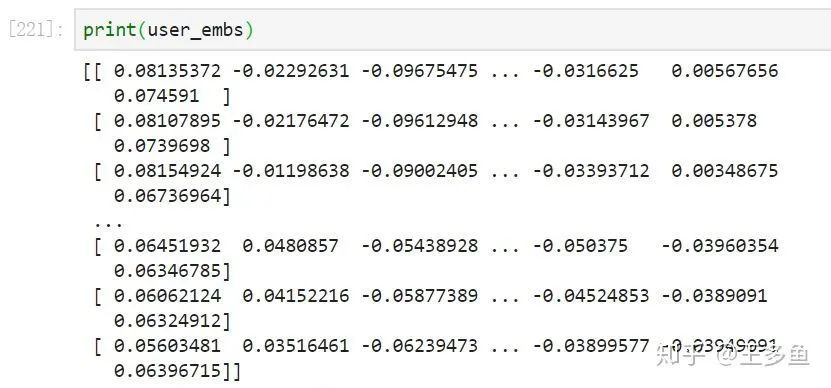
(2.6)获取用户端和电影端的Embedding表示
test_user_model_input = {"user_id": np.array(X["user_id"]), \ "gender": np.array(X["gender"]), \ "age": np.array(X["age"]), \ "hist_movie_id": np.array([[int(i) for i in l.split(',')] for l in X["hist_movie_id"]]), \ "hist_len": np.array(X["hist_len"])}
test_item_model_input = {"movie_id": np.array(X["movie_id"]), \ "movie_type_id": np.array(X["movie_type_id"])}
user_embedding_model = Model(inputs=model.user_input, outputs=model.user_embedding)item_embedding_model = Model(inputs=model.item_input, outputs=model.item_embedding)
user_embs = user_embedding_model.predict(test_user_model_input, batch_size=2 ** 12)item_embs = item_embedding_model.predict(test_item_model_input, batch_size=2 ** 12)print(user_embs)
(2.7)基于用户端和电影端的Embedding,通过python的annpy或faiss模块索引用户感兴趣的电影。
应用和实现可参考:
https://link.zhihu.com/target=https%3A//github.com/spotify/annoy
https://github.com/facebookresearch/faiss
参考:
https://link.zhihu.com/?target=https%3A//www.sci-hub.ren/10.1145/3298689.3346996


发表评论 取消回复