维基百科释义:
数据仓库是一种信息系统的数据存储理论,此理论强调利用某些特殊数据存储方式,让所包含的数据,特别有利于分析处理,以产生有价值的信息并依此作决策。
利用数据仓库方式所存放的数据,具有一但存入,便不随时间而更动的特性,同时存入的数据必定包含时间属性,通常一个数据仓库皆会含有大量的历史性数据,并利用特定分析方式,自其中发掘出特定信息。
Q1
何种数据存储方式更有利于分析处理?
OLAP(联机分析处理):是计算机技术中解决多维分析问题的一种方法;使用户能够从多个角度交互的分析多维数据;
例如:观看短视频的用户可以从某些角度(或维度)进行分析,包括是否付费用户、年龄、观看日期等等;
了解了数据分析处理工具后,我们就需要思考何种方式能将观看短视频的行为和维度数据(是否付费用户、年龄、观看日期)有效的组织;
解答:将数据分为事件表和维度表
事件表用于记录用户主动操作触发的埋点事件;
维度表用于记录某个特定属性的所有可能出现的情况,例如:性别维度表(1:男;0:女;-1:其他)、是否付费纬度表(true:付费用户;flase:白嫖用户)
附录:事件表与数据埋点的关系:
数据埋点需求一:增加视频点赞点击事件,需要知道点赞的视频信息;
event【事件】:Click
action【动作】:like(点赞)
position_source【位置】:video_detail
video_id【视频ID】:001
video_name【视频名称】:funk
creator_id【创作者名称】:110
….
数据埋点需求二:增加发布按钮点击事件,需要知道有发布意愿的人,用于创建发布漏斗
event【事件】:Click
action【动作】:publish_icon(发布按钮)
position_source【位置】:follow
….
数据埋点需求三:增加首页标签栏点击事件,分析tab交互行为,是被点击交互多还是页面滑动事件多
event【事件】:Click
action【动作】:home_tab(首页标签)
topic_name【标题名称】:explore
….
针对这三条需求,数据库事件表组织形式为:

针对上述解答,我们得出了一张事件表和多张维度表,可以看做是数据分析的基本表,那数据仓库中还涉及到的轻度汇总表和高级查询表如何组织呈现的,如何才能更有效的便于业务方查询呢?接下来介绍数据仓库分层结构;
通常数据仓库分为四层:
\1. ODS原始数据层:存放原始数据,例如用户操作行为的原始json日志数据;
ODS层数据通常需要经过日志审核系统,日志规则通常由大数据录入,在客户端上传日志时解析json文件进行规则校验,及时发现数据错误,进行协调修正;
\2. DWD明细数据层:粒度和ODS一致,对ODS层的数据按照规则进行清洗,例如缺失值的数据直接舍弃或者某些时间记录错误等等,在初期就要进行处理,防止对之后的分析造成影响;
\3. DWS服务数据层:对DWD层数据进行轻度汇总,对应到数据指标汇总表中的基础指标,当然也可以提少量的复合指标进行计算,DWS层数据表通常作为很多数据分析的底表,这样保证一次计算,多场景使用,提高数据计算效率;
\4. ADS数据应用层:统计报表层应用数据,对于高级复杂统计,高度依赖DWS层基础数据;
以启动事件为例:
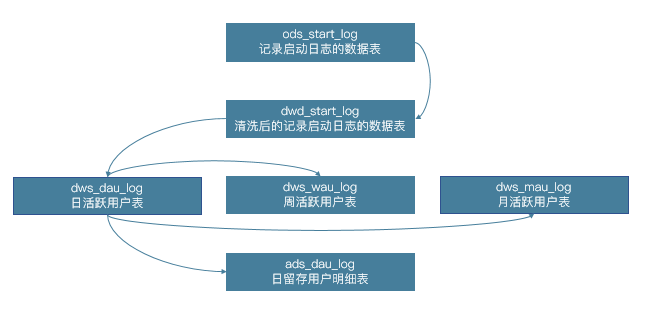
图示解读:
\1. ods层启动日志表汇总了所有用户的设备启动事件,设备启动事件即用户启动app,通常用于计算日活,也可以用于计算push消息的拉起成功率等等;
\2. dwd层的启动日志表将ods层数据中缺失用户id、缺失事件发生时间等等的值进行过滤、清洗;
\3. dws层根据dwd层清洗过的数据计算日活(用户当前启动过一次app即算作当日日活),通过日活也可以进一步计算周活、月活等等的基础数据;
\4. ads层数据较为复杂,根据日活先计算新增用户数(历史首次app启动的用户即为新增用户),进而计算第二日留存的用户占首日新增用户数的比例,即为首日新增用户的第二日留存率;
Q2
数据仓库为什么要分层?
\1. 数据安全性:通常为了数据安全,已经对原始数据做过一次甚至几次备份处理;但是对于加工后的数据,再无法确保加工过程100%稳定且安全情况下,就需要对原始数据进行保留,一旦加工过程发生故障或者错误,能够及时进行回溯,利用修改后的规则继续在原始数据集进行操作;
\2. 减少重复的开发工作:数据分析往往是复杂的过程,一个指标可能应用于多个分析过程,为了减少重复计算造成的计算负荷,数据仓库就需要分层,将简单的指标进行轻度汇总,便于高级查询访问处理,即达到一次计算多次使用的目的;
\3. 拆解复杂问题:对于一个复杂的查询条件,其往往会伴随着大量基础指标的计算,拆解后的基础指标能够让开发更清晰的明确所要完成分析的所有步骤,减少不必要的沟通成本;
Q3
数据仓库与数据集市区别?
对于短视频数据仓库而言,数据来自于创作者后台、BE后台(关注服务)、短视频内容库、行为数据仓库等等,打通所有的数据才能在数据分析中给予分析者更多的施展空间;
例如:对于视频的播放,包含的信息在各平台需要有:
l 创作者后台提供视频的所属创作者信息;
l BE后台提供创作者的所有增值服务;
l 短视频内容库提供视频的格式、视频时长、视频名称等等;
l 行为数据仓库提供用户点击行为发生的时间、地点、人物等等;
所有数据结合起来,在数据仓库中统一形成一条数据链路;
即,数据仓库涉及面更广,结合的数据更多,而数据集市则体量相对较小,包含的信息也更少;
Q4
数据仓库表关联分析常见问题?
以下部分会涉及到SQL内容,SQL基础请咨询阿北:xuqiugui_
如何分析用户活跃?
在启动日志中统计不同设备id 出现次数。
如何分析用户新增?
用活跃用户表 left join 用户新增表,用户新增表中mid为空的即为用户新增。
如何分析用户1天留存?
留存用户=前一天新增 join 今天活跃
用户留存率=留存用户/前一天新增
如何分析沉默用户?
按照设备id对日活表分组,登录次数为1,且是在一周前登录。
如何分析本周回流用户?
本周活跃left join本周新增 left join上周活跃,且本周新增id和上周活跃id都为null
如何分析流失用户?
按照设备id对日活表分组,且七天内没有登录过。
如何分析最近连续3周活跃用户数?
按照设备id对周活进行分组,统计次数大于3次。
如何分析最近七天内连续三天活跃用户数?
1)查询出最近7天的活跃用户,并对用户活跃日期进行排名
2)计算用户活跃日期及排名之间的差值
3)对同用户及差值分组,统计差值个数
4)将差值相同个数大于等于3的数据取出,然后去重,即为连续3天及以上活跃的用
连续更载中....
下一节:数据仓库—需求拆解实例(二)

一个数据人的自留地是一个助力数据人成长的大家庭,帮助对数据感兴趣的伙伴们明确学习方向、精准提升技能。
扫码关注我,带你探索数据的神奇奥秘





发表评论 取消回复