@毛毛
产品经理
集颜值和才华于一身。
对AI了解深入,经验丰富。
经过近几年来的发展,产品经理的岗位职责划分的越来越细,对能力的要求也越来越高。很多刚接手做AI产品的童鞋会困扰,到底需要对人工智能技术掌握到什么程度才能够胜任好这份工作。笔者通过自身的学习经验,期望能以此篇文章为刚入行或者想入行的童鞋打开一些学习思路。
1
工欲善其事,必先利其器
AI产品经理除了要掌握通用的产品技能,需要具有更强的专业性、广博性和条理性。AI技术作为一种新的生产力,处理了过往技术无法处理的复杂的非结构化数据。
很多人在使用机器学习时,喜欢简单粗暴的将数据丢给算法模型,期望从数据中自己得到结论。AI绝不是将手中的数据喂给它,就能够解决我们的业务问题。
很多公司老板容易AI超神论,认为我们掌握了技术,拥有了人才,就能够建立自己的护城河。作为产品经理需要清楚的理解机器学习的使用场景和边界,清晰定位问题才能寻找新的市场机会。
01
产品规划 - 五看三定原则
五看三定模型其实是华为的战略管理框架,现在把它结合到产品的工作中。
五看包括:
看行业/趋势:
结合公开的行业数据、现有的业务数据、产品数据分析未来趋势走向,为业务发展寻找新的增长点。
不仅要看宏观的经济因素还要从群体思想、政治关系等角度去切入,可以结合PEST方法进行分析,即政治、经济、社会、技术分别分析企业的外部环境。
看市场/客户:
确定需求强度,需求可替代性,以及客户的持续付费能力。
看竞争:
当前市场的竞争态势,有多少玩家在里面,分别占据了怎样的市场份额。
看自己:
评估内部资源,现有的产品矩阵。
看机会:
是否存在弯道超车的机会,做到人无我有,人有我优。
三定包括:
定控制点:
简单可理解为一种不易被构建及超越的中长期竞争力,控制有不同的维度,如成本优势、功能性能的领先、技术的壁垒、品牌与客户关系、绝对的市场份额等。
定目标:
制定清晰的战略目标,并拆解为最小任务,分步执行、监控、评估。
定策略:
策略即战术,策略的制定决定了后续的资源分配、系统如何组成。
02
选择产品类型
在开展新的业务线时,首先问自己几个问题:我们的护城河在哪?最终产品形态是什么样子?我们为市场提供了怎样的解决方案?服务方式?服务能力?面对不同的业务线首先要做到战略洞察所处环境与价值分析,制定清晰的战略目标和策略,通过五看三定原则合理的找到产品定位。
先发型产品:
拥有最快路径、利用产业升级进行驱动、建立核心门槛和护城河、资源消耗轻、塑造行业标准。
赶超型产品:
拥有最优路径、差异化的竞争驱动、对标核心竞品,寻找机会、研发资源投入较多、达到行业标准以上、做好客户服务。
2
数据需要懂多少?
01
建立数据认知
数据与信息的关系:
数据反映在事物属性的记录上,而信息是具体事物的表现形式,即数据经过加工和处理后,可揭示和转化为信息。
信息被识别后表示的符号为数据。
数据可以是连续的值比如声音、图像,也可以是离散的值,比如文字、符号;
计算机系统中,数据是以二进制0、1形式表示;
结构化数据和非结构化数据:
结构化的数据简单可以理解为数据库中的数据,可以结合具体的使用场景易于理解的数据。
非结构化的数据是指没有进行预定义,并且不方便用二维逻辑来表现和解释的数据,比如文本、图片、音频、视频..
何为脏数据:数据不再我们预先定义的范围内或对实际业务无意义。
02
了解数据的业务内涵
理解数据的业务内涵是非常关键的一步,这要求产品经理对业务的各个流程和关键节点要非常的熟悉,理解数据代表的含义,遇到模糊、定义不清晰的数据要充分与业务部门沟通,准确了解数据内涵。
业务数据包含但不局限于:
用户数据:
用户ID、性别、年龄、地区、手机号...
行为数据:
点击、分享、收藏、停留时间...
产品数据:
商品数据、订单数据、文章数据、详情页数据...
业务指标包含但不局限于:
用户指标:
新增用户、活跃用户数、留存用户数..
行为指标:
访问次数、转化率、转发率、流失率..
产品指标:
总量、收入、销量、好评率、差评率、成交量...
业务数据不独立存在,基于不同的业务背景可传达出不同的含义,数据的计算重组可发挥出极大的业务价值,需要基于自身的工作场景挖掘数据内涵。
03
数据处理流程和方法
数据处理流程包含了数据采集->数据处理->数据分析->数据应用->持续跟踪和验证。
数据采集
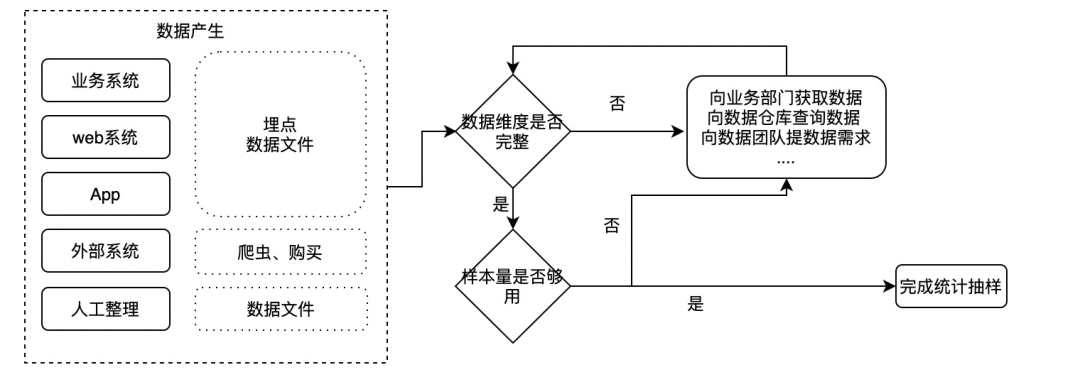
数据处理
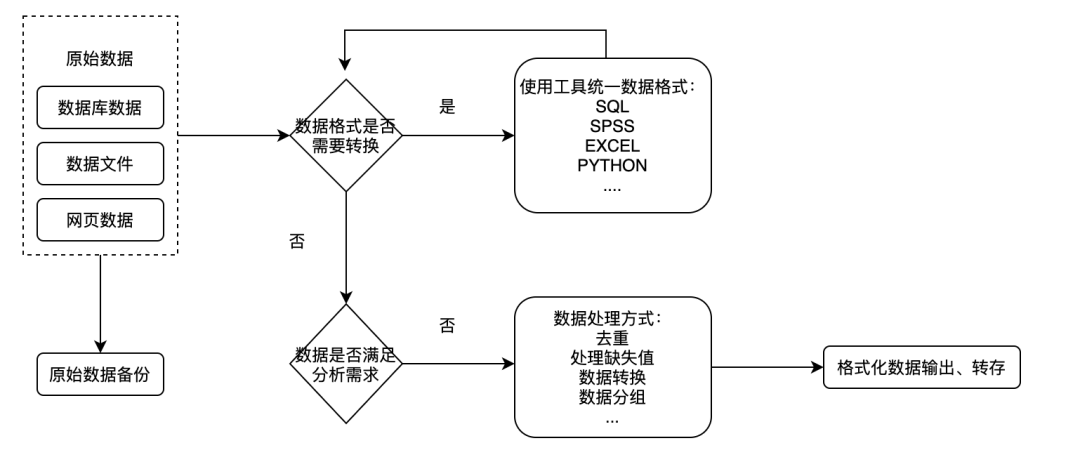
数据分析
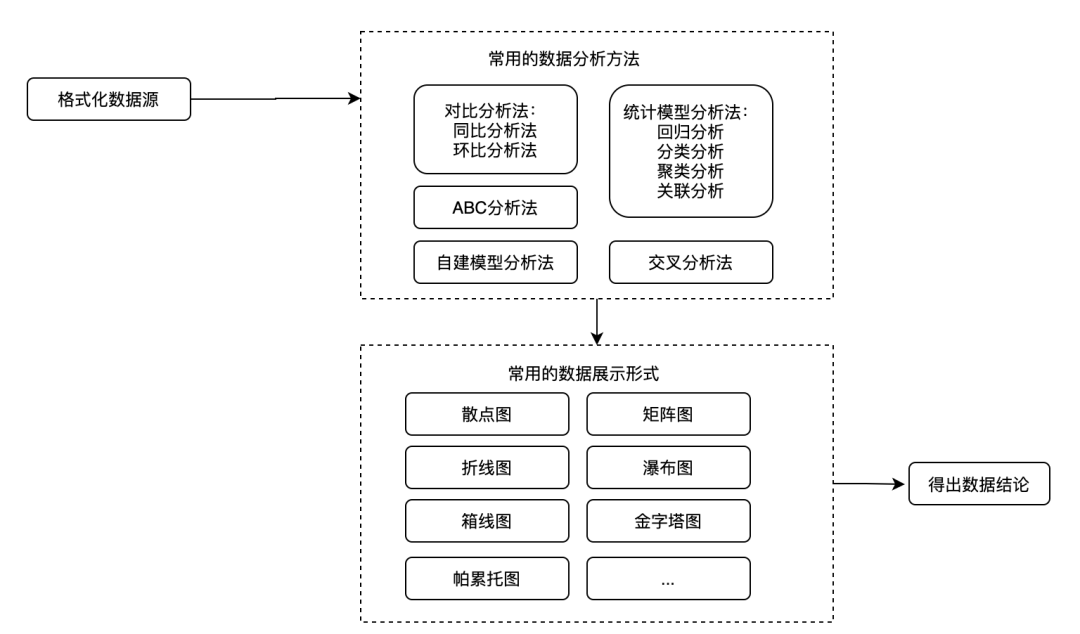
数据应用
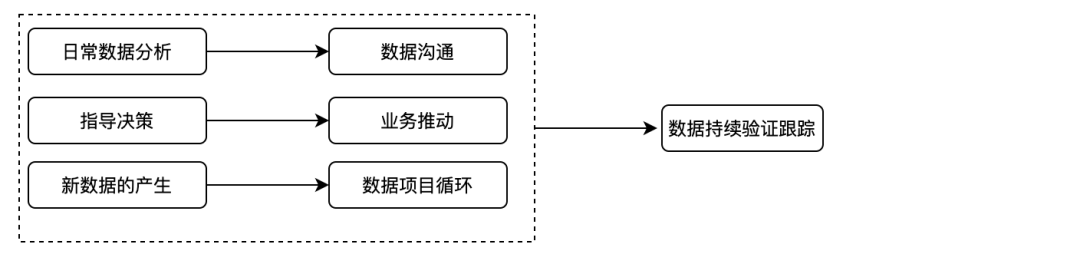
除此之外根据具体要解决的业务问题,还需要完成业务建模、数学建模、经验数据分析,此部分通常由数据分析师进行,产品经理涉及较少。
3
机器学习是什么?
机器学习为计算机提供了不同的数据处理方法,这些处理数据的方法可以直接从数据中学习,不需要额外的编程即可做出预测。我们可以将机器学习简单理解为函数,像理解y=x² 一样,给到一个输入项,通过公式的计算即可得出一个对应的计算结果。这个公式不需要编码预设逻辑,由数据的规律计算得出。
机器学习过程分为训练阶段和预测阶段。
训练阶段需要提前准备一定的历史数据(即公式的x和y),通过机器学习算法,训练出一套可计算的公式(即模型)。
预测阶段就是拿真实的数据(x),在训练好的模型上进行输入,观察输出的结果(y),是否符合预期,若符合预期即完成了一个机器学习模型的训练。
01
从任务来看
机器学习解决的问题可以归为分类问题、预测问题。
分类问题包含二分类、多分类,顾名思义,二分类问题是非此即彼的问题,如垃圾邮件,只存在是垃圾邮件、不是垃圾邮件;
图片识别问题,是植物不是植物。
多分类问题如文档自动归类,包含了一对多,多对多的关系。
预测问题通常第一反应就会想到回归,因为常被用来预测公司收入、业务增长量、商品销量。
需要预估的通常都是连续值,试图将输入变量和输出用一个连续函数对应起来。
而分类问题,通常预测的都是离散值,试图将输入变量与离散的类别对应起来。
还有一类特殊的解决问题的模型为结构化学习模型,通常输出的数据不再是一个固定长度的值,比如图片语义分析,对应输出的是图片对应的文字描述。
02
从机器学习方法来看
机器学习分为有监督学习、半监督学习、无监督学习、迁移学习、强化学习。
有监督:
训练样本带有标签
半监督:
训练样本部分有标签,部分无标签
无监督:
训练样本全部无标签
迁移学习:
把已经训练好的模型参数迁移到新的模型上来帮助新模型的训练
强化学习:
也叫学习最优策略,是可以让本体在特定环境下,根据不同状态做出行动,以此来获得最大回报。
03
从模型类别来看
机器学习模型主要分为线性模型、非线性模型。
线性模型是指因变量和自变量之间按比例表现出线性对应关系,包含了线性回归、多项式回归。
公式表现为h(x)=w1x1+w2x2+⋯+wnxn+b。
非线性模型通常是指因变量与自变量间不能在坐标空间中表现出线性对应关系。
常见的SVM、KNN、决策树、深度学习都属于非线性模型。
提到线性、非线性模型,我们必须要了解一下什么是损失函数,通常在模型训练的过程中,我们需要观察h(x)与y之间的差距,也就是均方误差,在线性模型中表现为L(h)=m∑i=1(y(i)−h(x(i)))2,在模型训练过程中,损失函数是作为度量函数好坏的标准。
需要注意的是在面对不同的问题时,所使用的损失函数形式是存在差异的,常见的损失函数有均方差损失函数、交叉熵损失函数、合页损失函数,通常会配合不同的算法使用做出突出表现。
04
常见的误差
泛化误差:
可以分解为偏差、方差和噪声之和。
偏差:
反映了模型在样本上的期望输出与真实标记之间的差距,指模型本身的精准度,以及拟合能力。
方差:反映了模型在不同训练数据集下学得的函数的输出与期望输出之间的误差,通常是为了测试模型的稳定性,观察预估结果的波动情况。
在模型训练过程中,需要根据实际情况来权衡模型的复杂度,使偏差和方差得到均衡,以整体误差最小的原则去评估。
05
常见的问题
模型训练中常常遇到欠拟合、过拟合的情况,那么怎么识别及解决呢。
欠拟合:通常是指模型刻画不够,解决方案通常有三种。
(1)寻找更好的特征提升数据刻画能力。
(2)增大数据集数量。
(3)模型复杂度低,重新选择更加复杂的模型。
过拟合:与欠拟合相反,模型刻画太细,泛化能力太差。通常解决方案为。
(1)减少特征的维度,将高维空间密度增大,也就是通常说的降维。
(2)加入正则化项,使模型褶皱减少,更加平滑。
4
问题三:算法需要懂多少?
确认算法的流程通常是由产品经理和算法工程师共同完成,包含:需求确定 -> 算法设计 -> 算法讨论 -> 算法确认 -> 算法验收 -> 持续改进。
算法模型的选择和训练是个繁琐且复杂的过程,依赖于具体所解决问题的复杂程度。产品经理除了要明确定位要解决的核心问题,还需要了解模型训练的整个流程。
很多人会说产品经理不需要了解这么多,不是还有算法工程师吗?理想情况下,如果你的算法工程师能够充分了解要解决的业务场景,并将数据可解决问题的上限、下限划定清楚,产品经理只需验收数据效果即可。但通常情况下,算法工程师距离业务线较远,而机器学习强依赖于数据表现,产品经理对业务数据的识别能力,通常能够极大的加快整体进度,在训练过程中能够及时识别问题并调整策略及解决方案。
产品经理对算法的掌握到底需要达到什么程度呢?个人认为只需要掌握常见算法模型的原理和使用场景,以及不同算法在解决不同问题的优势和劣势,合理组合和使用即可满足日常的工作需求。不需要纠结于具体的算法推导过程。
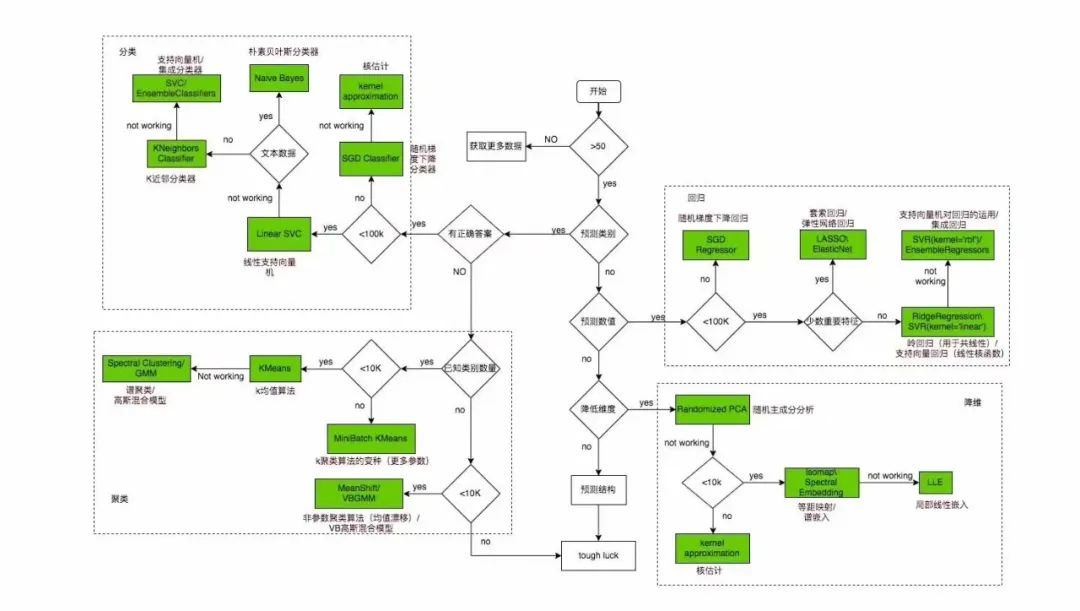
机器学习常见的算法模型
针对不同的使用场景,scikit-learn(python机器学习库)上有封装好的机器学习算法模型可以支持我们直接调用。下图为人工整理的关于不同场景及数据集下建议使用的算法模型,仅供学习和参考。下期将介绍具体的机器学习训练过程,包含如何梳理业务逻辑、需求转化、准备数据集、建立算法模型、模型评估及训练过程中常出现的问题与解决方案。



发表评论 取消回复